这段时间一直在处理数据采集的问题,目前平台数据采集趋于稳定,可以抽出时间来整理一下近期的成果,顺便介绍一些近期用到的技术。本篇文章偏向技术,需要读者有一定的技术基础,主要介绍数据采集过程中用到的神器mitmproxy,以及平台的一些技术设计。以下是数据采集整体的设计,左边是客户机,在里面放置了不同的采集器,采集器发起请求之后,通过mitmproxy访问抖音,等数据回传之后,通过中间的解析器对数据进行解析,最后分门别类的存储到数据库中,为了提升性能,在中间加入了缓存,把采集器和解析器分隔开,两个模块之间工作互不影响,可以最大限度的把数据入库,下图为第一代架构设计,后续会有一篇文章介绍平台架构设计的三代演化史。<br>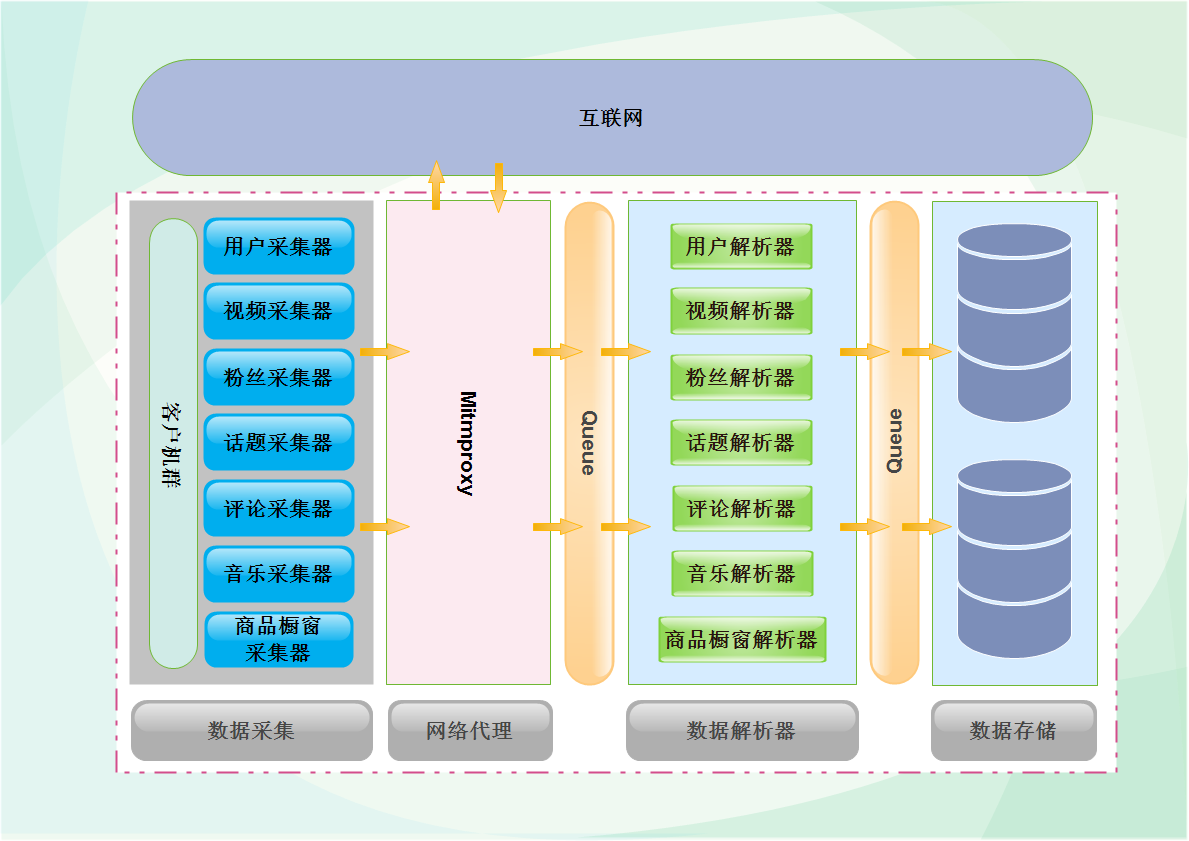
准备工作
开始进入数据采集的准备工作,第一步自然是环境搭建,本次我们在windows环境下,采用python3.6.6环境,抓包和代理工具是mitmproxy,也可以使用Fiddler抓包,采用夜神模拟器来模拟安卓运行环境(也可以用真机),这次主要通过手动滑动app来抓取数据,下次介绍采用Appium自动化工具,实现数据采集的全自动(解放双手)。<br>1、安装python3.6.6环境,安装过程可自行百度,需要注意的是,centos7自带的是python2.7,需要升级到python3.6.6环境,升级之前主要先安装ssl模块,否则升级好的版本无法访问https的请求。<br>2、安装mitmproxy,安装好python环境后,在命令行执行pip install mitmproxy安装mitmproxy,注:windows下只有mitmdump和mitmweb可以使用,安装好后在命令行输入mitmdump即可启动,默认启动的代理端口为8080。<br>3、安装夜神模拟器,可以在官网下载安装包,安装教程自行百度即可,基本都是下一步。安装好夜神模拟器之后,需要对夜神模拟器进行配置。首先需要设置模拟器的网络为手动代理,IP地址为windows的IP,端口为mitmproxy的代理端口。<br>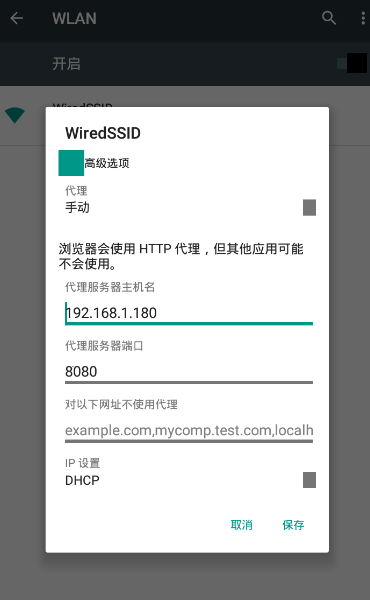 <br>4、接下来是证书的安装,打开模拟器中的浏览器,输入地址mitm.it,选择对应版本的证书,安装好后,就可以进行抓包了。<br>
<br>4、接下来是证书的安装,打开模拟器中的浏览器,输入地址mitm.it,选择对应版本的证书,安装好后,就可以进行抓包了。<br> <br>5、安装app,app安装包可以到官网下载,然后通过拖拽进模拟器就可以安装,或者在应用市场进行安装。<br>至此,本次数据采集环境就全部搭建完成。
<br>5、安装app,app安装包可以到官网下载,然后通过拖拽进模拟器就可以安装,或者在应用市场进行安装。<br>至此,本次数据采集环境就全部搭建完成。
数据接口分析 抓包
搭建好环境之后就开始对抖音app进行数据抓包,分析出每个功能所使用的接口,本次以采集视频数据接口为例介绍。<br>关闭之前打开的mitmdump,重新打开mitmweb工具,mitmweb是一个图形化的版本,就不用对着黑框框找了,如下图:<br> <br>启动之后打开模拟器的抖音app,可以看到已经有数据包解析出来了,然后进入用户主页,开始下滑视频,在数据包列表中可以找到请求视频数据的接口https://aweme.snssdk.com/aweme/v1/aweme/post/<br>
<br>启动之后打开模拟器的抖音app,可以看到已经有数据包解析出来了,然后进入用户主页,开始下滑视频,在数据包列表中可以找到请求视频数据的接口https://aweme.snssdk.com/aweme/v1/aweme/post/<br>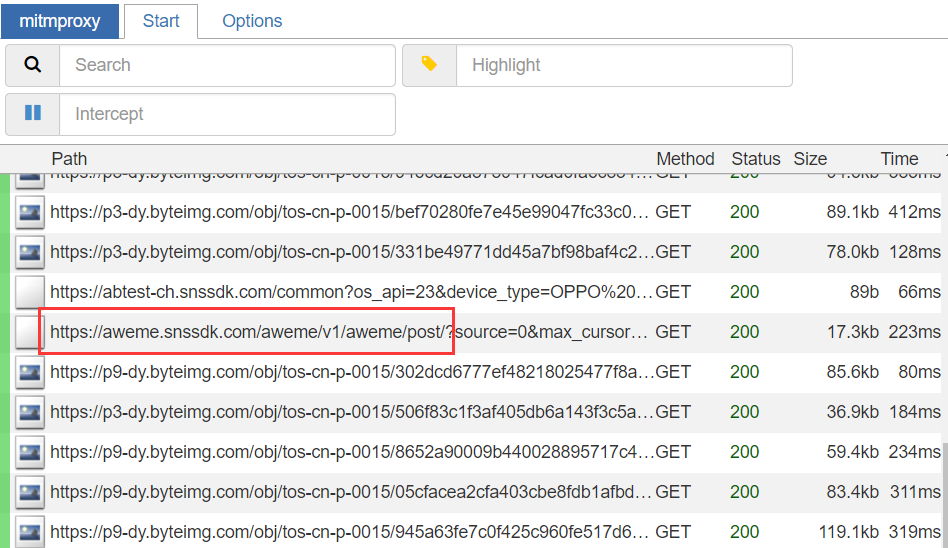 <br>可以在右边看到接口的请求数据和响应数据,我们将响应数据复制出来,进入下一步解析。<br>
<br>可以在右边看到接口的请求数据和响应数据,我们将响应数据复制出来,进入下一步解析。<br>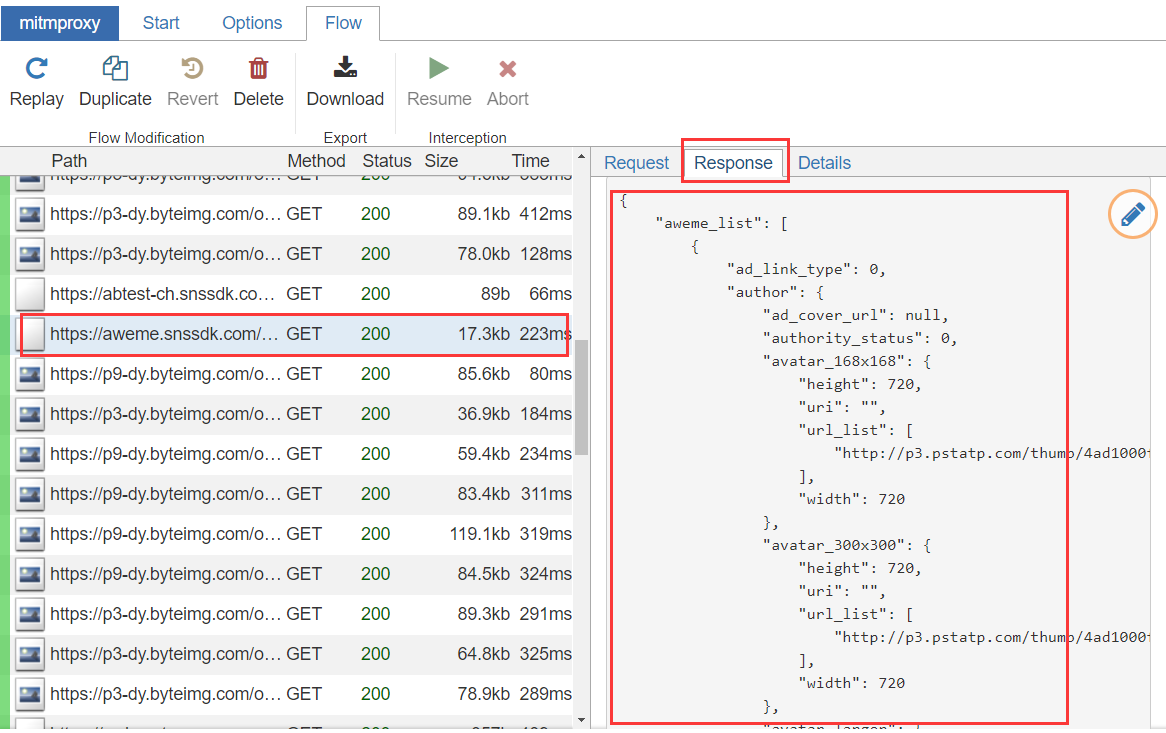
数据解析
通过mitmproxy和python代码的结合,我们就可以在代码中获取到mitmproxy中的数据包,进而可以按照需求来处理。新建一个test.py文件,里面放两个方法:
def request(flow):
pass
def response(flow):
pass
见名知意,这两个方法,一个是在请求的时候执行的,一个是在响应的时候执行,而数据包则存在于flow当中。通过flow.request.url可以获取到请求url,flow.request.headers可以获取到请求头信息,flow.response.text中的就是响应的数据了。
def response(flow):
if str(flow.request.url).startswith("https://aweme.snssdk.com/aweme/v1/aweme/post/"):
index_response_dict = json.loads(flow.response.text)
aweme_list = index_response_dict.get('aweme_list')
if aweme_list:
for aweme in aweme_list:
print(aweme)
这个aweme就是一个完整的视频数据了,可以根据需要提取里面的信息,这里提取部分信息做介绍。
"statistics":{
"aweme_id":"6765058962225204493",
"comment_count":24,
"digg_count":1465,
"download_count":1,
"play_count":0,
"share_count":3,
"forward_count":0,
"lose_count":0,
"lose_comment_count":0
}
statistics信息就是这个视频的点赞,评论,下载,转发的数据。<br>share_url为视频的分享地址,通过这个地址,可以在PC端观看抖音分享的视频,也可以通过这个链接解析到无水印视频。<br>play_addr为视频的播放信息,其中的url_list即为无水印地址,不过目前官方做了处理,这个地址无法直接播放,也有时间限制,超时之后链接就失效了。<br>有了这个aweme,就可以把里面的信息解析出来,保存到自己的数据库,或者下载无水印视频,保存到自己电脑了。<br>写好代码之后,保存test.py文件,cmd进入命令行,进入到保存test.py文件目录下,在命令行输入mitmdump -s test.py,mitmdump就启动了,此时打开app,开始滑动模拟器,进入用户主页:<br> <br>开始不断下滑,test.py文件就可以把抓取到的视频数据全部解析出来了,以下是我截取的部分数据信息:<br>视频信息:<br>
<br>开始不断下滑,test.py文件就可以把抓取到的视频数据全部解析出来了,以下是我截取的部分数据信息:<br>视频信息:<br>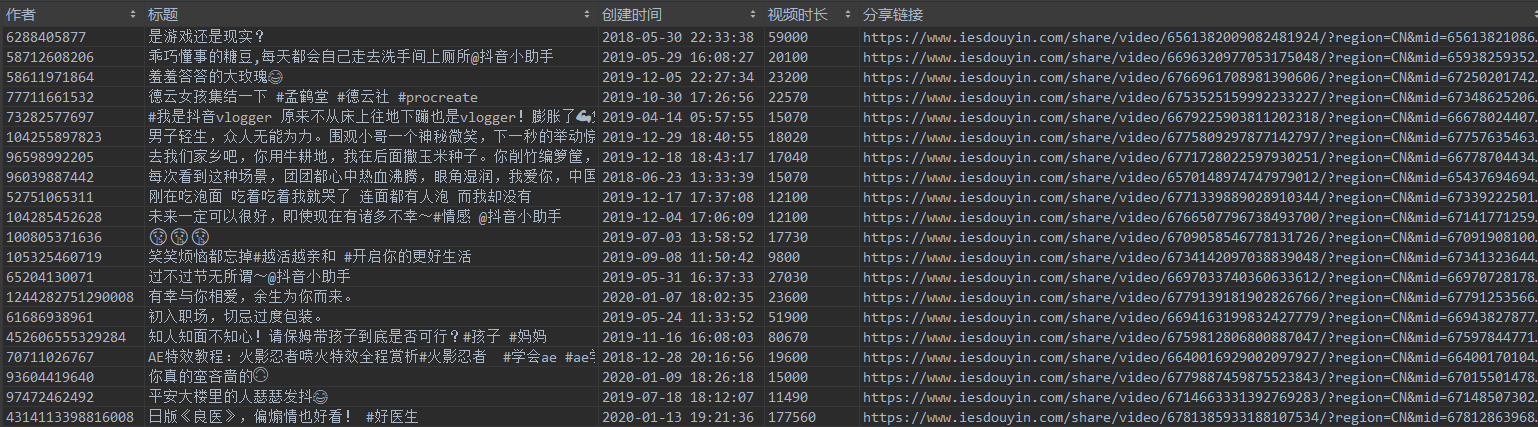 <br>视频统计数据:<br>
<br>视频统计数据:<br>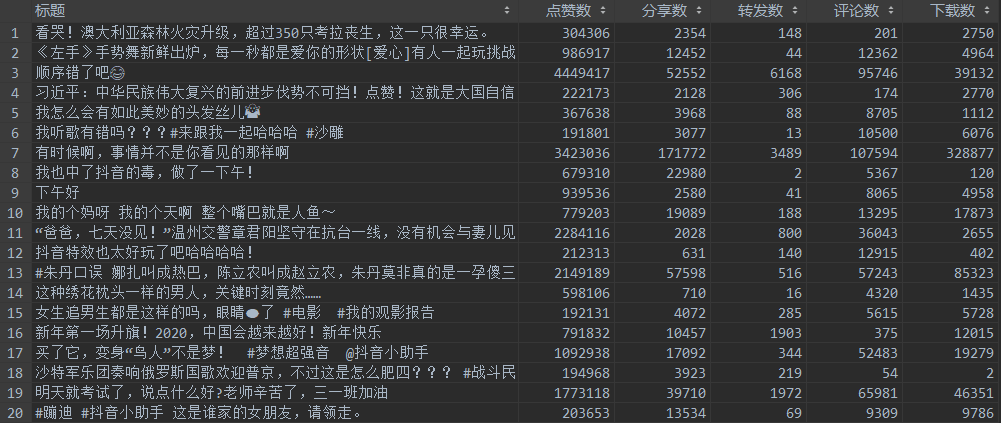 <br>视频评论数据:<br>
<br>视频评论数据:<br>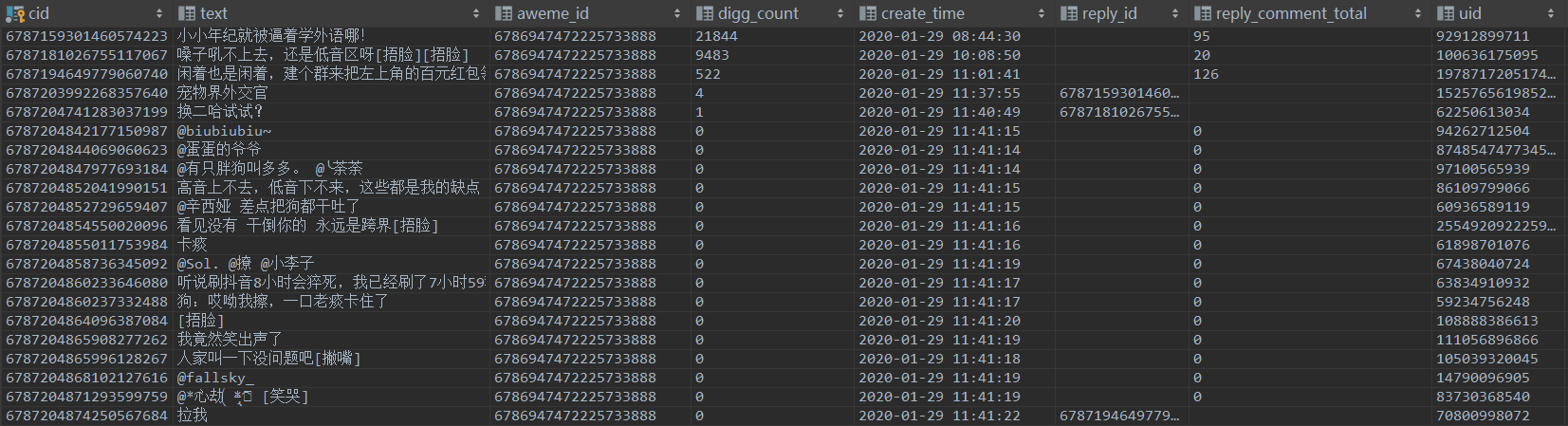 <br>无水印视频下载:<br>
<br>无水印视频下载:<br>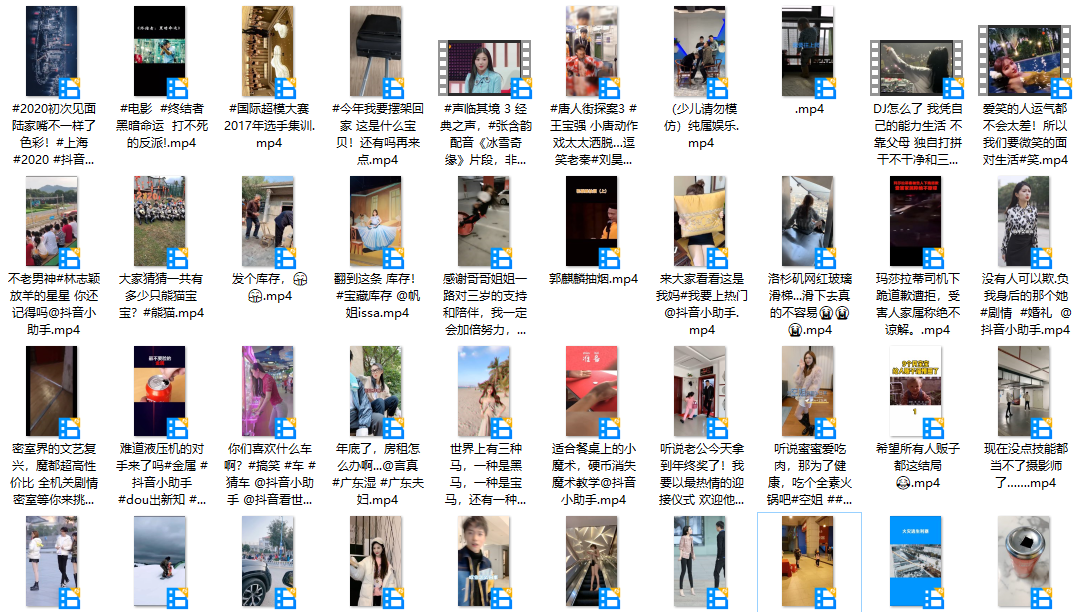 <br>本次介绍就到这里结束了,主要是运用mitmdump配合python代码来解析数据,下次讲讲怎么运用appium,怎么实现自动化滑动模拟器,实现这个程序的全自动抓取视频数据,以及把采集下来的数据进行处理之后,得到的一些成果展示。<br>
<br>本次介绍就到这里结束了,主要是运用mitmdump配合python代码来解析数据,下次讲讲怎么运用appium,怎么实现自动化滑动模拟器,实现这个程序的全自动抓取视频数据,以及把采集下来的数据进行处理之后,得到的一些成果展示。<br>
更多抖音,快手,小红书数据实时采集接口,请查看文档: TiToData
来源:oschina
链接:https://my.oschina.net/u/2293598/blog/4809285