一、上线规划
一般 redis 的参数配置都在 redis.conf 中,在上线前根据实际环境配置好合适参数,能有效提高 redis 的可用性。
-
redis 的运行机器 CPU 不求核数多,但求主频高,Cache大,因为 redis 主处理模式是单进程的。
-
留意 redis 日志文件的配置,对应 logfile 参数。redis.log 为 redis 主日志,sentinel.log 为 sentinel 监控日志。
-
关闭 THP,这个默认的 Linux 内存页面大小分配策略会导致 RDB 时出现巨大的 latency 和巨大的内存占用。关闭方法为:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
-
一定要设置最大内存 maxmemory 参数,否则物理内存用爆了就会大量使用 Swap,写 RDB 文件时的速度很慢。设置的参数参考:机器内存 * 45% / 1.2。(1.2 为内存碎片)
-
maxmemory-policy 策略,则当 redis 内存数据达到 maxmemory 时,会根据 maxmemory-policy 配置来淘汰内存数据,以避免OOM。
- noeviction:不执行任何淘汰策略,当达到内存限制的时候客户端执行命令会报错,把redis当做DB时,推荐使用。
- allkeys-lru:从所有数据范围内查找到最近最少使用的数据进行淘汰,直到有足够的内存来存放新数据。
- volatile-lru:默认,从所有的最近最少访问数据范围内查找设置到过期时间的数据进行淘汰,如果查找不到数据,则回退到 noeviction。
- allkeys-random:从所有数据范围内随机选择key进行删除。
- volatile-random:从设置了过期时间的数据范围内随机选择key进行删除。
- volatile-ttl:从设置了过期时间的数据范围内优先选择设置了TTL的key进行删除。
-
持久化配置。在配置上有三种选择:不持久化,RDB,RDB + AOF(默认)。另外,如果为主从复制关系,建议主服务器关闭持久化。
# RDB 持久化配置
save 900 1 #在900秒(15分钟)之后,如果至少有 1 个key发生变化,则 dump 内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有 10 个key发生变化,则 dump 内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有 10000 个key发生变化,则 dump 内存快照。
# AOF 持久化配置
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no #从不同步。高效但是数据不会被持久化。
- redis 使用的是单进程(除持久化时),所以在配置时,一个实例只会用到一个CPU。那么如何指定 redis 使用的 CPU 呢?
#显示进程运行的CPU (15361 为 redis-server 的进程号)。显示结果的 f 实际上是二进制4个低位均为 1 的 bitmask,每一个 1 对应于 1 个CPU,表示该进程在 4 个CPU上运行
[root@localhost redis] taskset -p 15361
pid 15361's current affinity mask: f
#指定进程运行在某个特定的CPU上。该命令的 3 表示 CPU 将只会运行在第 4 个CPU上(从0开始计数)
[root@localhost redis] taskset -pc 3 15361
pid 15361's current affinity list: 0-3
pid 15361's new affinity list: 3
二、常见运维操作
服务功能运维
- 启动 redis:redis-server redis.conf
- 启动 redis-sentinel:redis-sentinel sentinel.conf
- 停止 redis,注意 kill -9 关闭可能会丢失数据:redis-cli shutdown
- 验证密码(或在连接的时候指定密码):auth password(/usr/bin/redis-cli -a 123456)
- 查看配置:config get *
- 修改配置:
# 临时配置
127.0.0.1:6379> config set requirepass 123456
OK
# 永久配置,将目前服务器的参数配置写入 redis.conf
127.0.0.1:6379> config rewrite
OK
# 永久配置也可通过直接修改 redis.conf 的方式
-
选择数据库(默认连接的数据库是0,默认数据库数量是16个):select db-index
-
将 key 从当前数据库移动到指定数据库:move key db-index
-
清空当前数据库,生产上禁止使用:flushdb
-
清空所有数据库,生产上禁止使用:flushall
-
RDB 持久化命令:
- BGSAVE:后台子进程进行RDB持久化
- SAVE:主进程进行RDB,生产环境千万别用,服务器将无法响应任何操作
- LASTSAVE: 返回上一次成功SAVE的Unix时间
-
AOF 持久化命令:BGREWRITEAOF
-
设定 crontab 定时备份持久化数据:cp /var/lib/redis/dump.rdb /somewhere/safe/dump.$(date +%Y%m%d%H%M).rdb
-
执行 lua 脚本:redis-cli --eval myscript.lua key1 key2 , arg1 arg2 arg3
-
发送原始的 redis protocl 格式数据到服务器端执行: echo -en '*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n' | redis-cli -a 123456 --pipe
服务性能运维
- 查看连接的客户端:client list
- 探测服务是否可用(返回 pong 说明正常):ping
- 探测服务延迟,千兆网卡一般延迟在 0.16ms 左右:
[root@localhost redis]# redis-cli --latency
min: 0, max: 5, avg: 0.24 (1874 samples)
-
查看统计信息:info
- total_connections_received:redis 连接数
- latest_fork_usec:上次导出 rdb 快照,持久化花费时长(微秒), 用来检查是否有人使用了 SAVE 命令
- used_memory: 由 redis 分配器分配的内存总量,以字节(byte) 为单位
- used_memory_rss:返回 redis 已分配的内存总量(俗称常驻集大小),包含了 used_memory 和内存碎片
- mem_fragmentation_ratio:used_memory_rss / used_memory 的值,1.N为佳,如果此值过大,说明 redis 的内存的碎片化严重,可以导出再导入一次(重启)
-
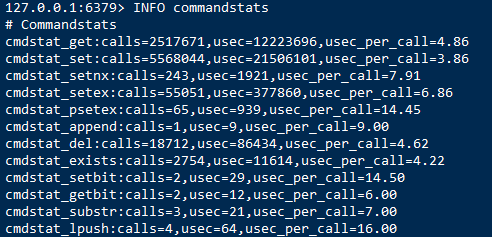
统计命令执行所耗费的毫秒数(每个命令的总时间和平均时间):INFO commandstats

-
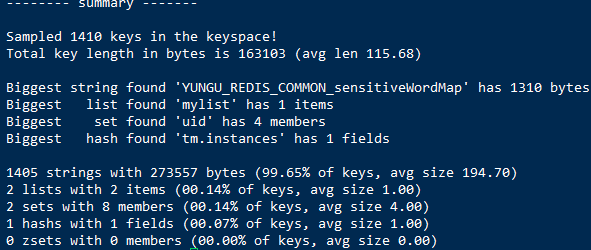
统计 redis 数据存储中比较大的key(用 scan 的方式对 redis 中的 key 进行采样,寻找较大的 keys):redis-cli --bigkeys
-
获取慢查询:
# 得到慢查询列表,默认保留 128 条(slowlog-max-len 参数)
127.0.0.1:6379> slowlog get 10
1) 1) (integer) 1 # 查询ID
2) (integer) 1572146706 # 发生时间
3) (integer) 12239 # 运行时长,该时间不包含网络延迟(微秒)
4) 1) "save" # 原命令
2) 1) (integer) 0
2) (integer) 1569327858
3) (integer) 391725
4) 1) "GET"
2) "YUNGU_REDIS_ADMIN_ACCESS_TOKEN_5E6A833C21A87983459A985753AE5425"
# 清空慢查询
127.0.0.1:6379> slowlog reset
OK
三、测试方法
- 模拟oom,redis 直接退出:redis-cli debug oom
- 模拟宕机:redis-cli debug segfault
- 模拟 redis 线程挂起:redis-cli -p 6379 debug sleep 30
- 快速产生测试数据:debug populate
127.0.0.1:6379> dbsize
(integer) 1410
127.0.0.1:6379> debug populate 100
OK
127.0.0.1:6379> dbsize
(integer) 1510
- 模拟 RDB 加载情形(save 当前的 rdb 文件,并清空当前数据库,重新加载 rdb):debug reload
- 模拟 AOF 加载情形(清空当前数据库,重新从aof文件里加载数据库):debug loadaof
来源:oschina
链接:https://my.oschina.net/u/4356412/blog/3289475