Hive优化
主要内容

提问方式:不会直接问你优化方式有哪些?而是问你在项目中遇到过什么问题?怎么解决的?
(1)Fetch 抓取

(2)本地模式

- 当输入的数据量十分小时,考虑采用本地模式进行优化;
- 开启本地模式不一定数据就一定就走本地,还需要保证:1 输入的数据量要小于128M;2 输入的文件个数要小于4;
(3)表的优化
① 小表、大表 Join

② 大表 Join 大表
1 空 KEY 过滤

2 空 key 转换

(解决了数据倾斜的问题)
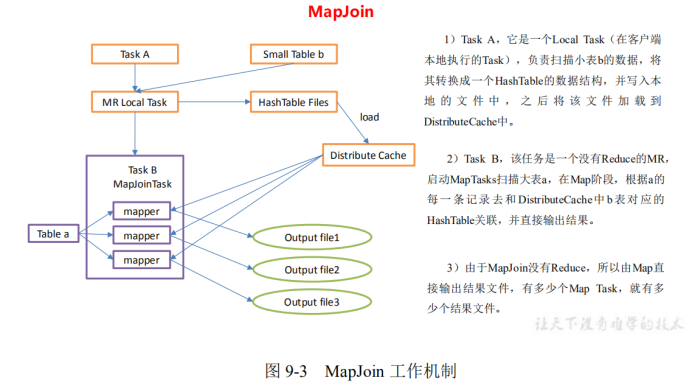
③ MapJoin

MapJoin工作原理:
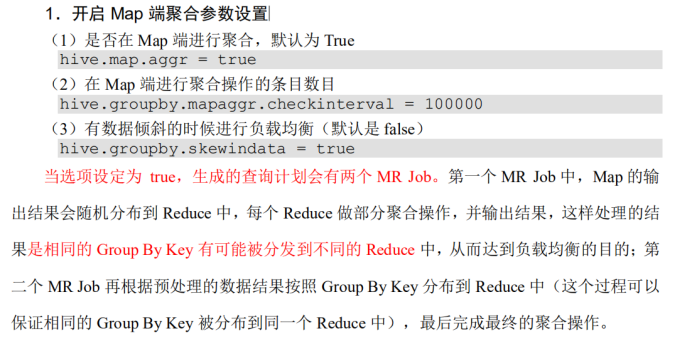
④ Group By

⑤ Count(Distinct) 去重统计

⑥ 行列过滤

行处理就是在表关联前,先用过滤条件筛选数据。
⑦ 采用分区、分桶技术
(4)MR优化
① 合理设置 Map 数

② 小文件进行合并

③ 复杂文件增加 Map 数

④ 设置合理的Reduce 数

来源:oschina
链接:https://my.oschina.net/u/4419899/blog/4526208