随着大数据技术在各行各业的广泛应用,要求能对海量数据进行实时处理的需求越来越多,同时数据处理的业务逻辑也越来越复杂,传统的批处理方式和早期的流式处理框架也越来越难以在延迟性、吞吐量、容错能力以及使用便捷性等方面满足业务日益苛刻的要求。
在这种形势下,新型流式处理框架Flink通过创造性地把现代大规模并行处理技术应用到流式处理中来,极大地改善了以前的流式处理框架所存在的问题。
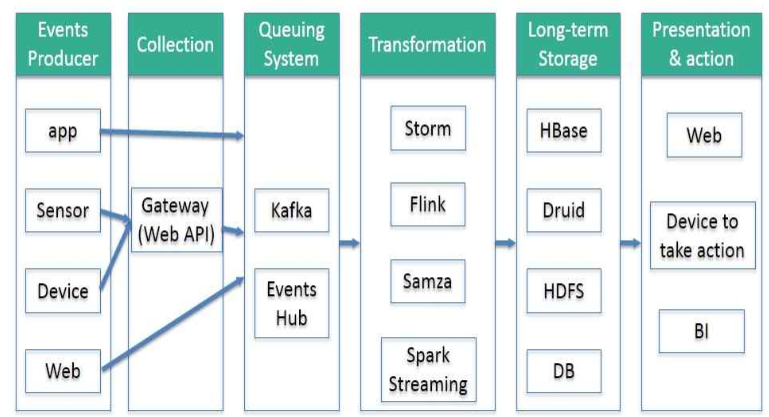
一句话:flink是etl的工具。
flink的层次结构:
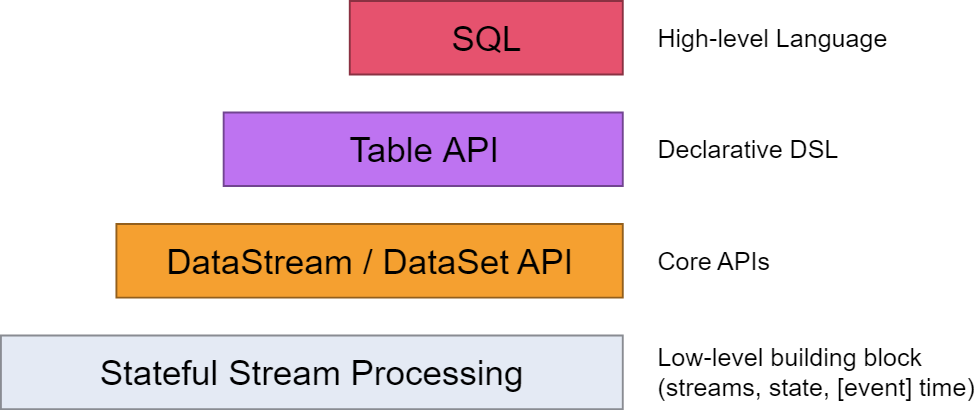
其中,
windows下flink示例程序的执行 简单介绍了一下flink在windows下如何通过flink-webui运行已经打包完成的示例程序(jar)
从flink-example分析flink组件(1)WordCount batch实战及源码分析讲到DataSet的转换
从flink-example分析flink组件(2)WordCount batch实战及源码分析----flink如何在本地执行的?flink batch批处理如何在本地执行的
从flink-example分析flink组件(3)WordCount 流式实战及源码分析 flink stream流式处理如何在本地执行的?
使用flink Table &Sql api来构建批量和流式应用(1)Table的基本概念介绍了Table的基本概念及使用方法
使用flink Table &Sql api来构建批量和流式应用(2)Table API概述介绍了如何使用Table
使用flink Table &Sql api来构建批量和流式应用(3)Flink Sql 使用 介绍了如何使用sql
flink dataset api使用及原理 介绍了DataSet Api
flink DataStream API使用及原理介绍了DataStream Api
flink中的时间戳如何使用?---Watermark使用及原理 介绍了底层实现的基础Watermark
flink window实例分析 介绍了window的概念及使用原理
Flink中的状态与容错 介绍了State的概念及checkpoint,savepoint的容错机制
flink的特征
最后,给出官网给出的特征作为结束:
1、一切皆为流(All streaming use cases )
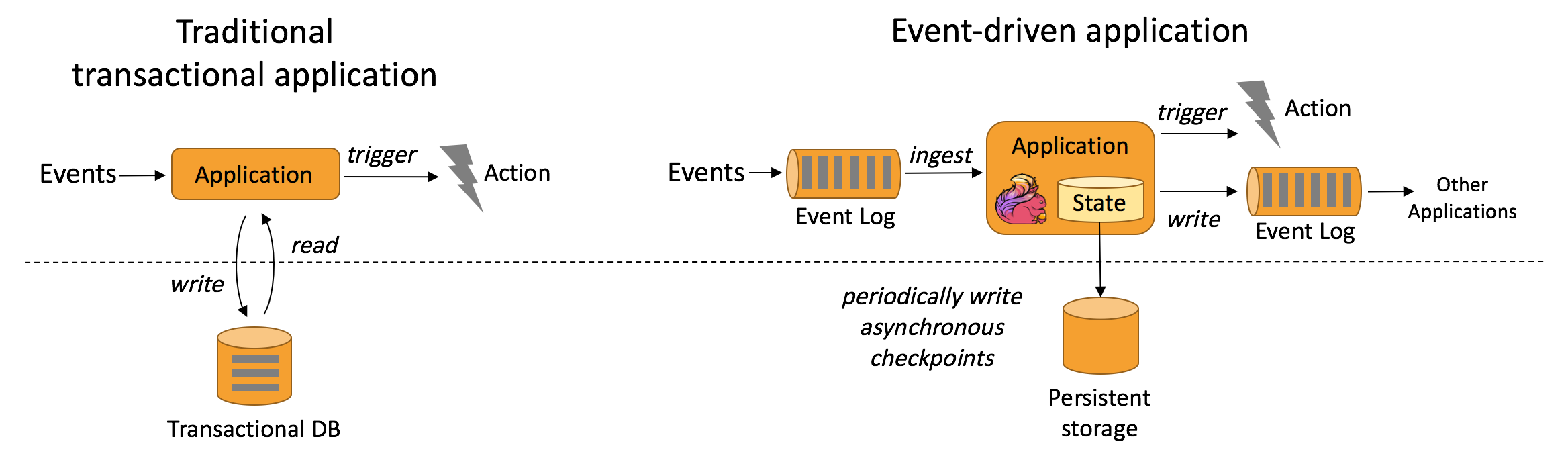
- 事件驱动应用(Event-driven Applications)
- 流式 & 批量分析(Stream & Batch Analytics)
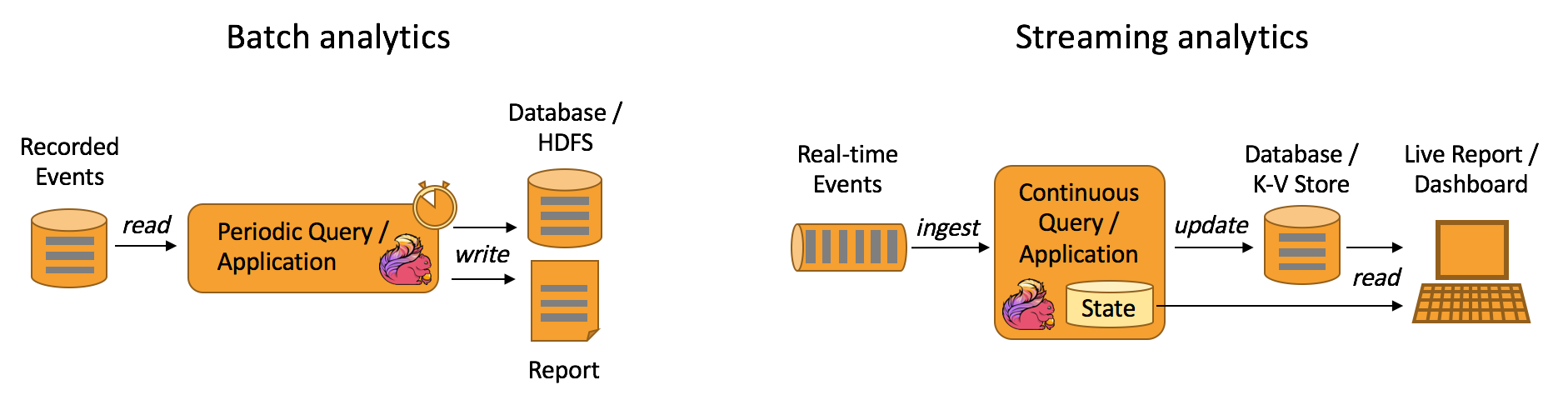
- 数据管道&ETL(Data Pipelines & ETL)
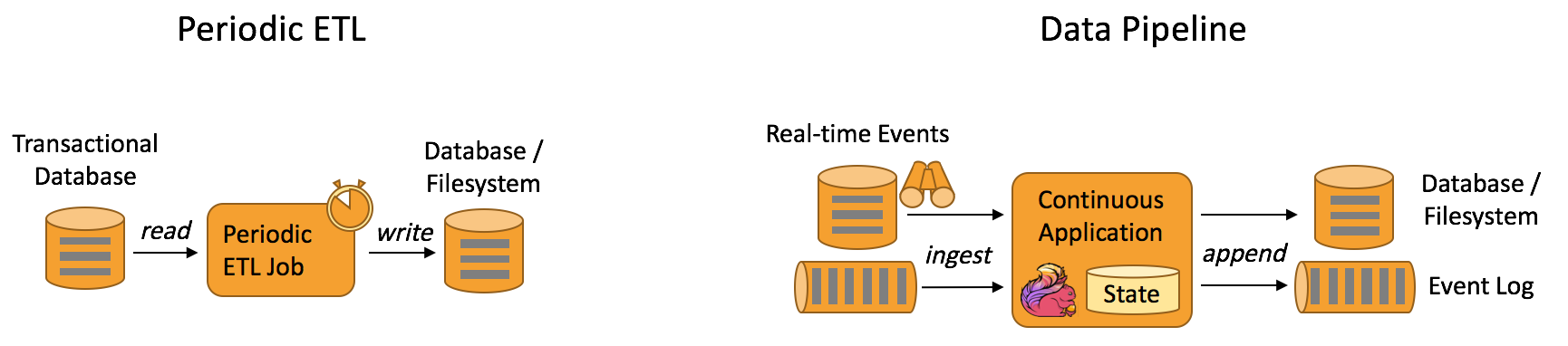
2、正确性保证(Guaranteed correctness)
- 唯一状态一致性(Exactly-once state consistency)
- 事件-事件处理(Event-time processing)
- 高超的最近数据处理(Sophisticated late data handling)
3、多层api(Layered APIs)
- 基于流式和批量数据处理的SQL(SQL on Stream & Batch Data)
- 流水数据API & 数据集API(DataStream API & DataSet API)
- 处理函数 (时间 & 状态)(ProcessFunction (Time & State))
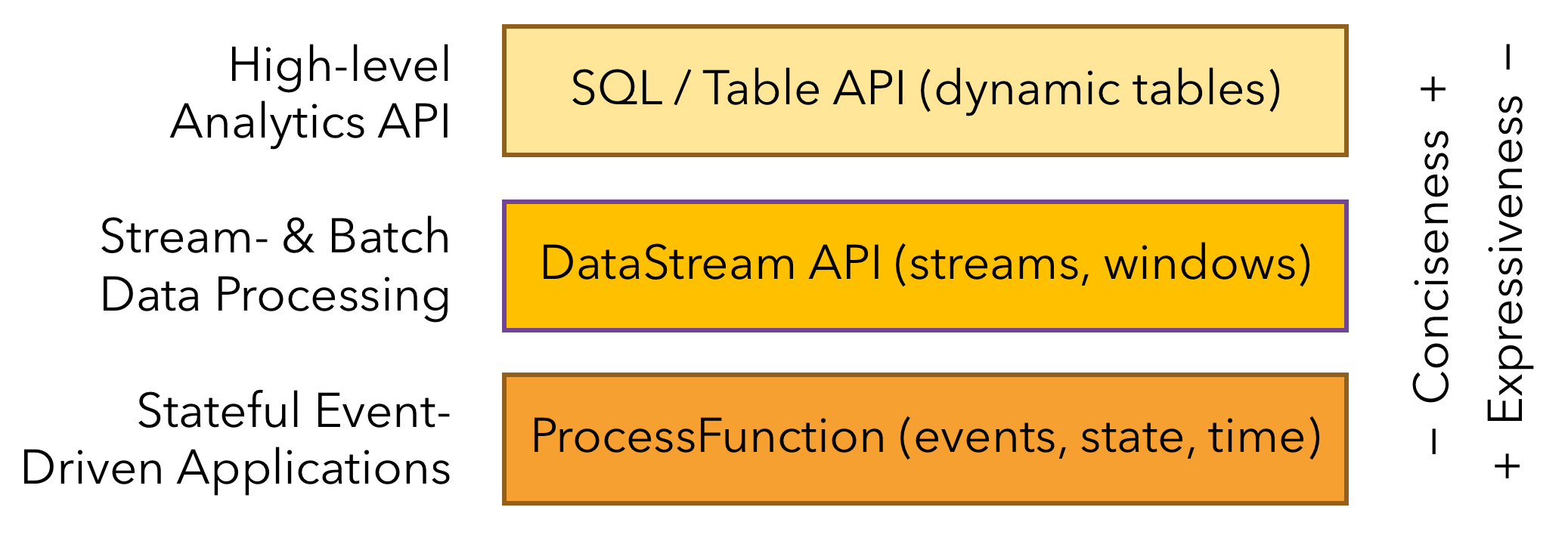
4、易用性
- 部署灵活(Flexible deployment)
- 高可用安装(High-availability setup)
- 保存点(Savepoints)
5、可扩展性
- 可扩展架构(Scale-out architecture)
- 大量状态的支持(Support for very large state)
- 增量检查点(Incremental checkpointing)
6、高性能
- 低延迟(Low latency)
- 高吞吐量(High throughput)
- 内存计算(In-Memory computing)
flink架构
1、层级结构
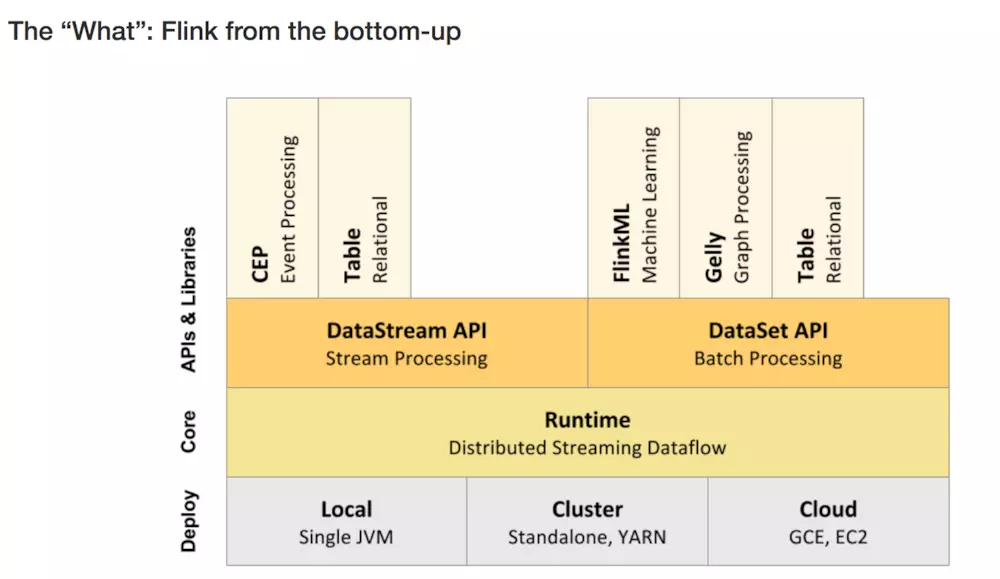
2.工作架构图
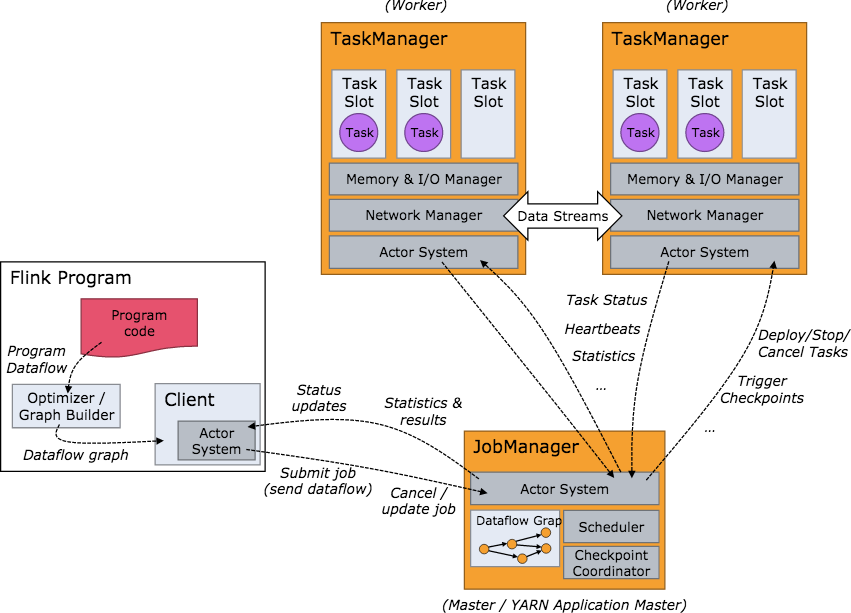
原文出处:https://www.cnblogs.com/davidwang456/p/11256748.html
来源:oschina
链接:https://my.oschina.net/u/4311595/blog/3257952