参考大佬文章
https://blog.csdn.net/weixin_43622131/article/details/110565692
https://blog.csdn.net/weixin_43622131/article/details/110621405
说在前面
以下实验过程都是在使用docker搭建好spark集群的前提条件下进行,如果你的spark集群还没有搭建成功,可以参考我的上一篇博客
https://blog.csdn.net/weixin_45548774/article/details/110206515
下面是正式的实验内容
启动spark集群
1本机启动集群do
直接运行
spark-shell
或者进入spark安装目录,打开spark-shell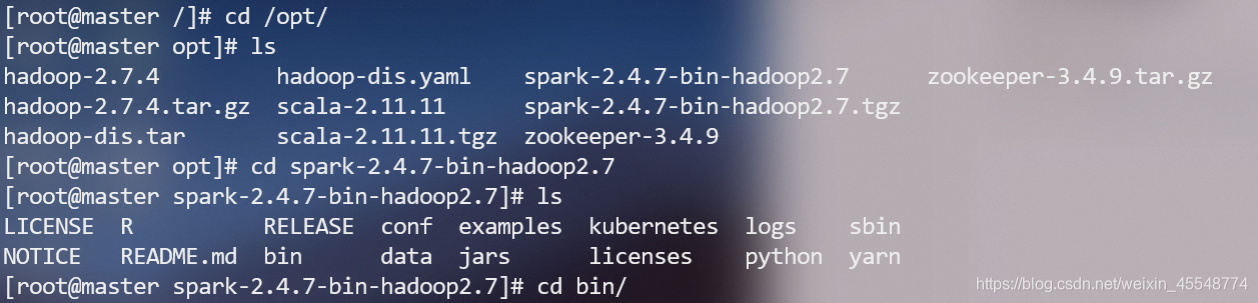
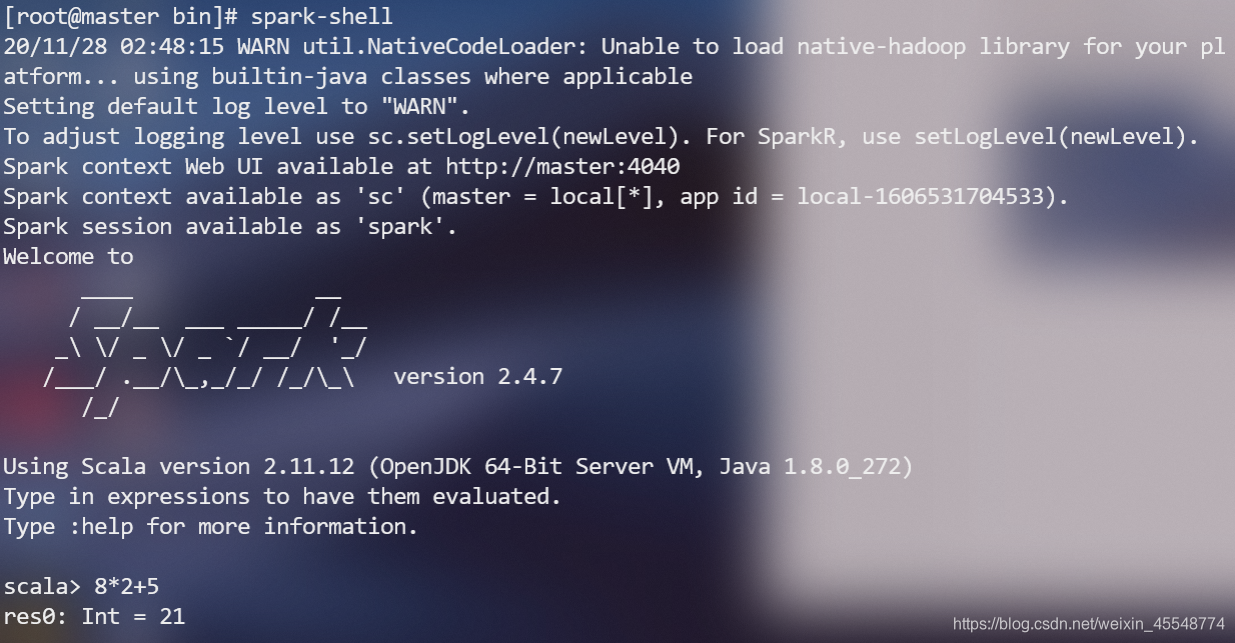
2通过yarn启动spark集群
使用命令
spark-shell --master yarn
或者
spark-shell --master yarn-client
这期间可能会遇到如下问题:
1 Name node is in safe mode.
这是因为在分布式文件系统启动的时候,开始的时候会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期通过命令也可以进入安全模式。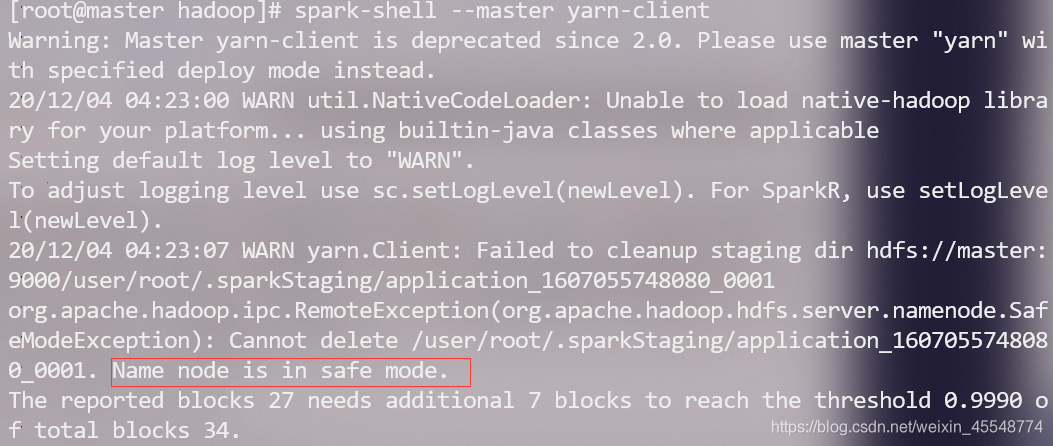
通过以下命令来解决:
hadoop dfsadmin -safemode leave
2

出现这个问题可以
参考博客
https://www.cnblogs.com/yy3b2007com/p/9247621.html
上面说的很清楚
确保集群可以正常启动后就可以开始进入正题了!!!
Windows中使用IDEA写程序,手动生成jar包,手动提交到docker搭建的spark集群上运行
配置IDEA的环境
1 下载IDEA
这里给出官网链接https://www.jetbrains.com/idea/download/#section=windows
下载后安装即可
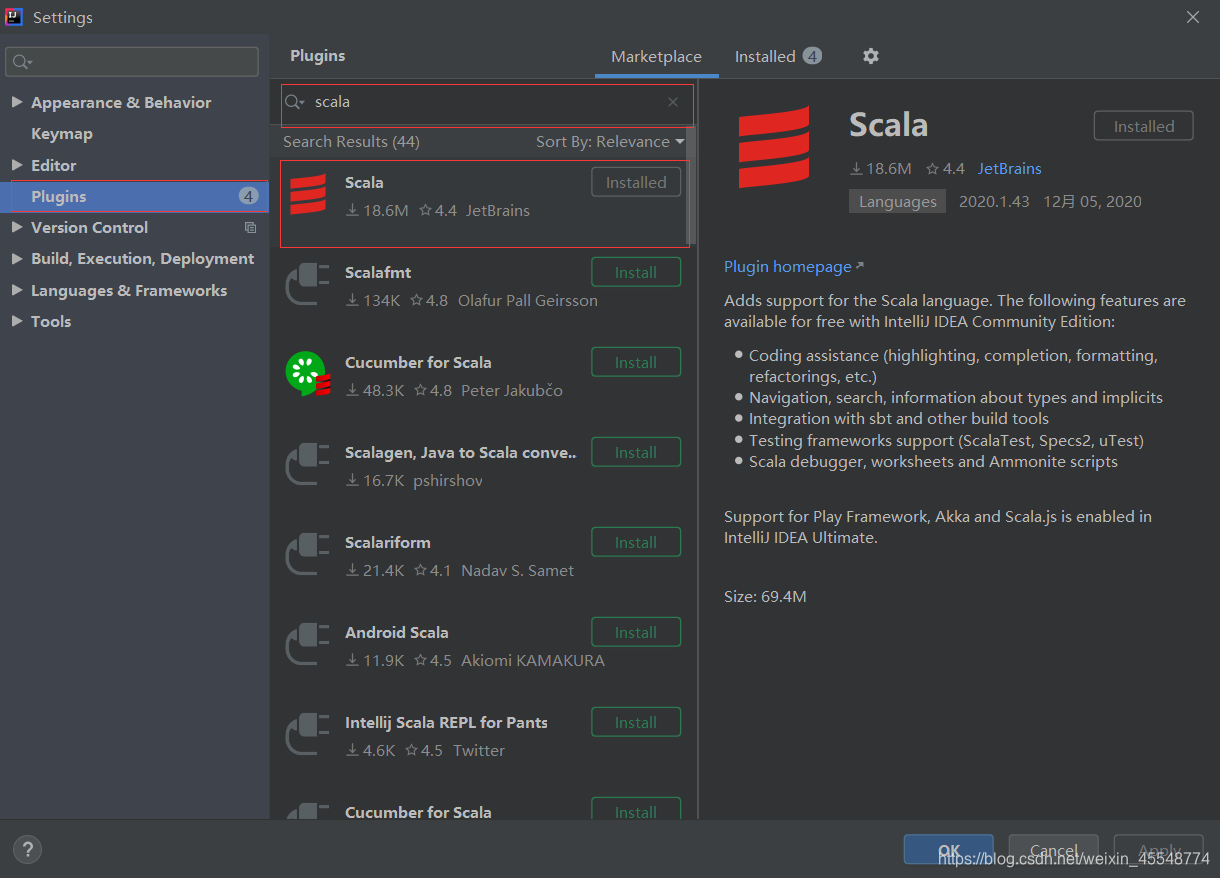
2 在IDEA中下载scala
3 在IDEA中创建scala工程
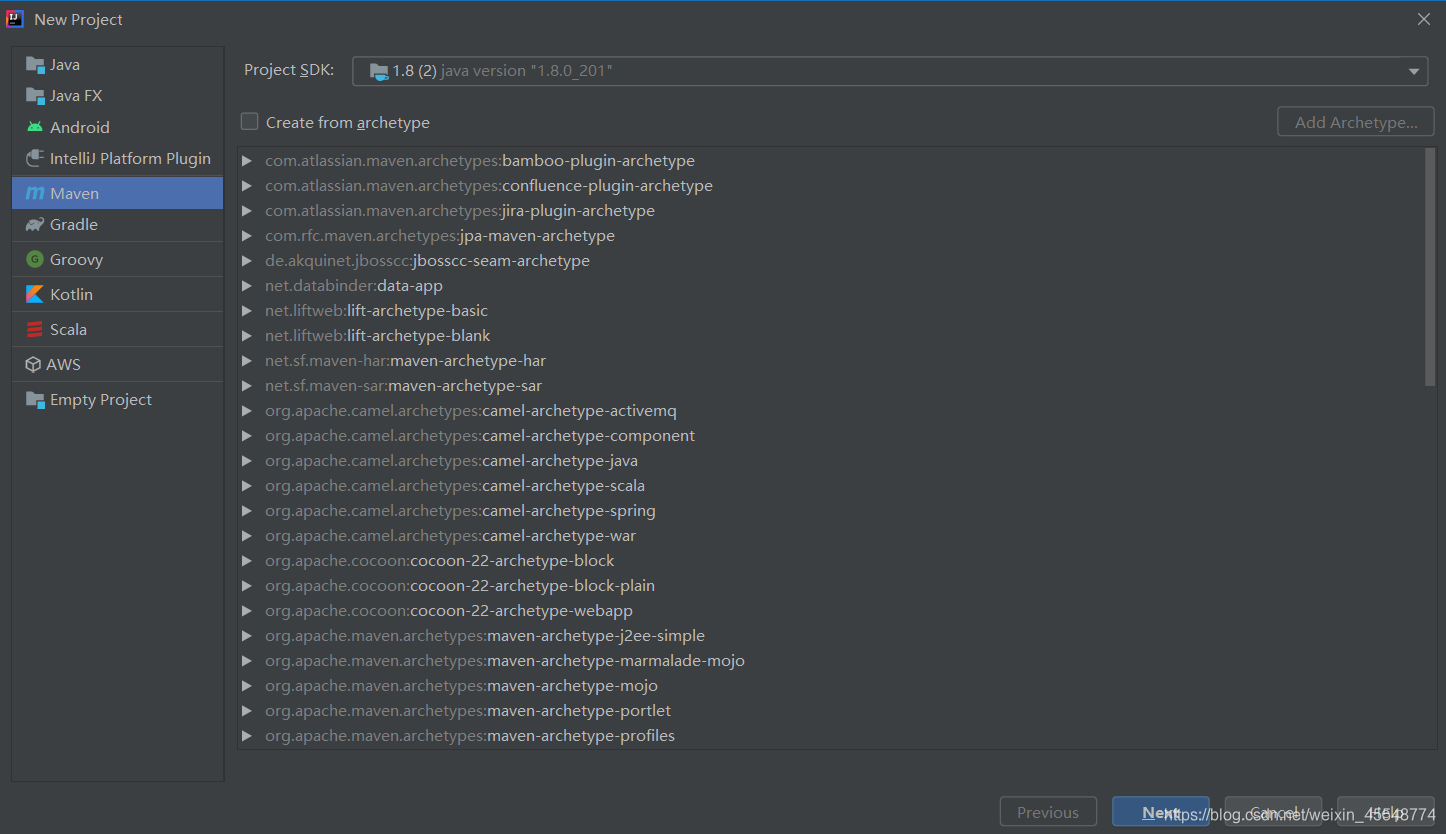
填写信息
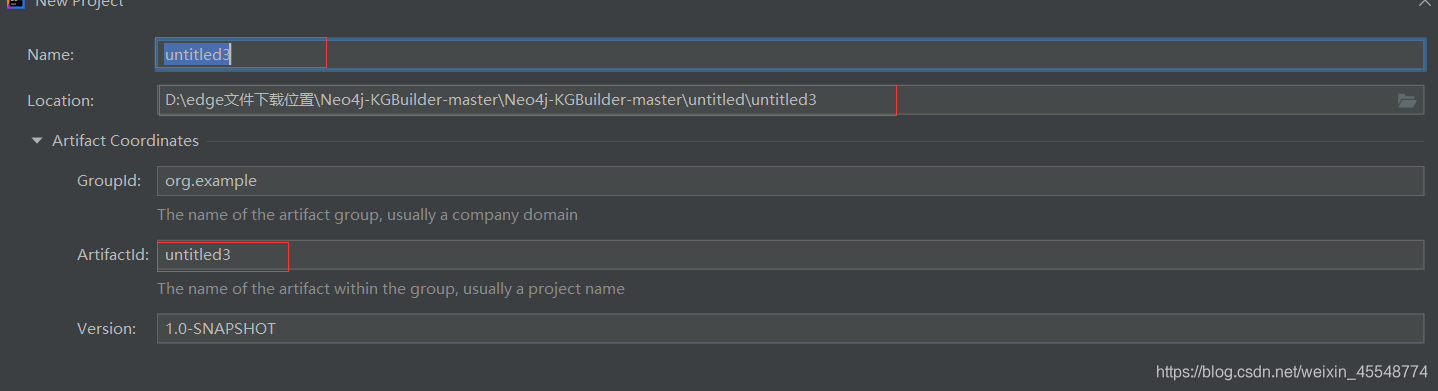
标红的地方可以自己修改,其他不变即可,点击finish
新建scala文件夹,并设置为源目录
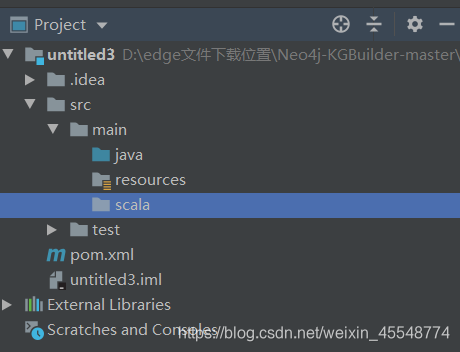
右键scala
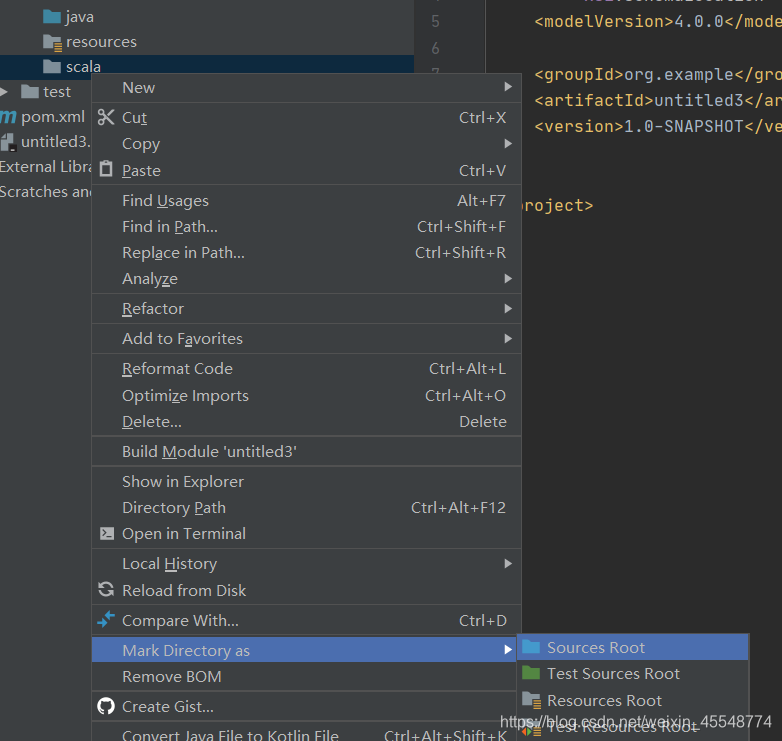
4 导入scala环境
点击File中的Project Structure,进入到下图页面,添加scala的SDK,可以从下面链接中下载
链接:https://pan.baidu.com/s/11DYs4lS-wZjtnHRuFC9_DQ
提取码:u18t
下载后解压即可

点击Browse
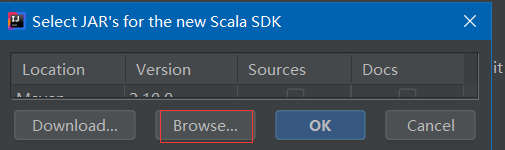
在下载的文件中选择lib,点击ok即可
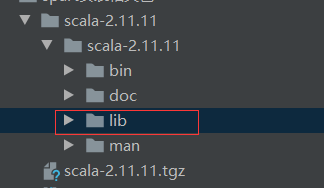
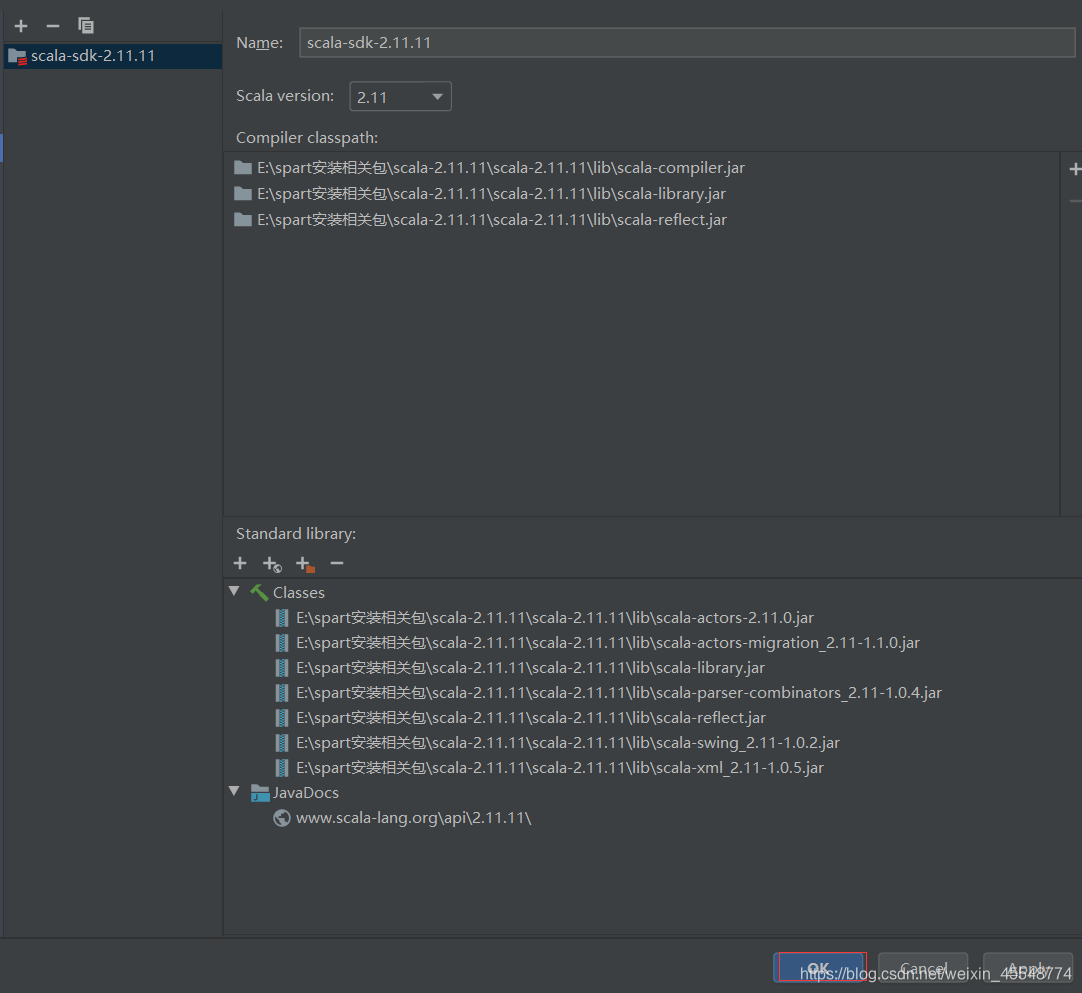
5 编写pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>untitled3</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.version>2.11</scala.version>
<hadoop.version>2.7.4</hadoop.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
</project>
6 将spark源码里的jars包直接加到library中
点击Modules然后点击添加
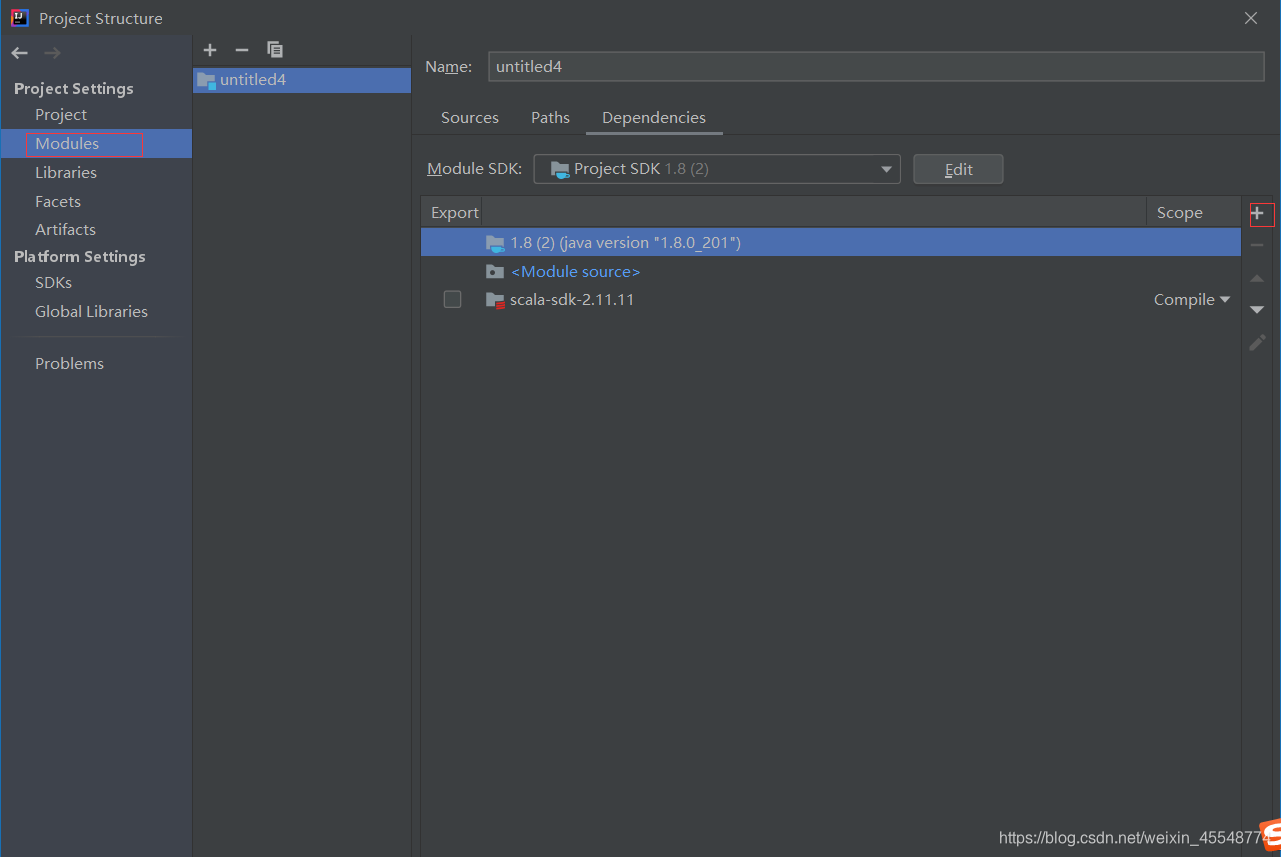
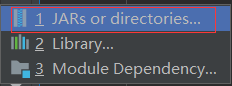
将下载jars导入就可以了,jars可以在下面链接中下载
链接:https://pan.baidu.com/s/1GFiIvteJu2m94GdjcYxViA
提取码:kx8o
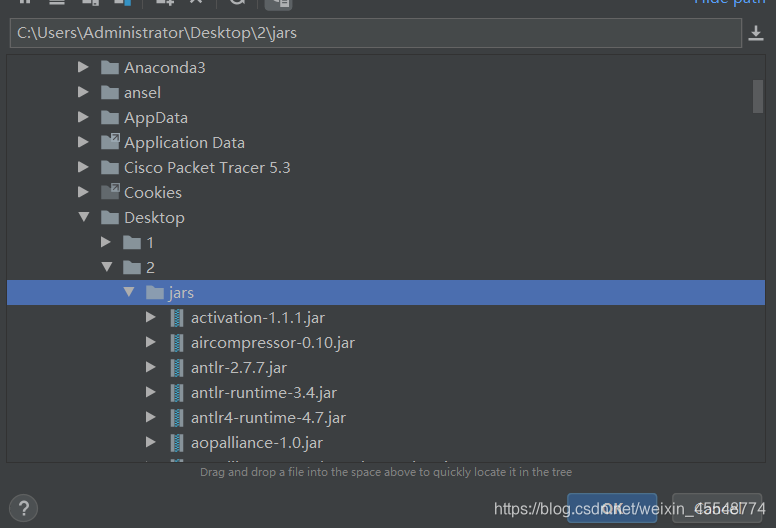
上传之后环境就基本配置完成了
7 运行一个scala程序
新建scala的class,

点击Object,输入名字

建成之后,运行第一个scala程序
object Hello_World {
def main(args: Array[String]) {
println("hello")
}
}
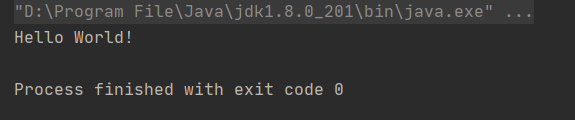
打包scala程序
进入这个
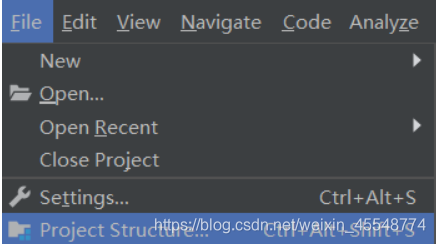
然后
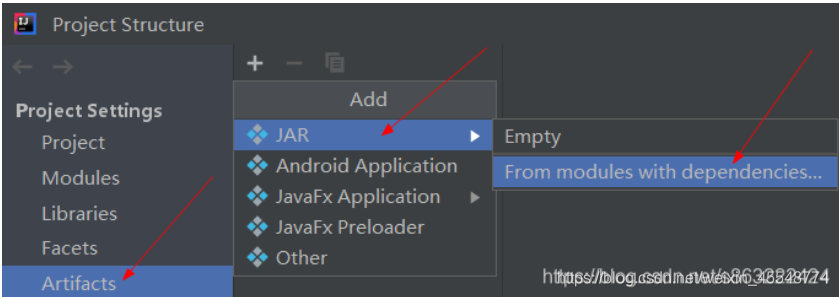
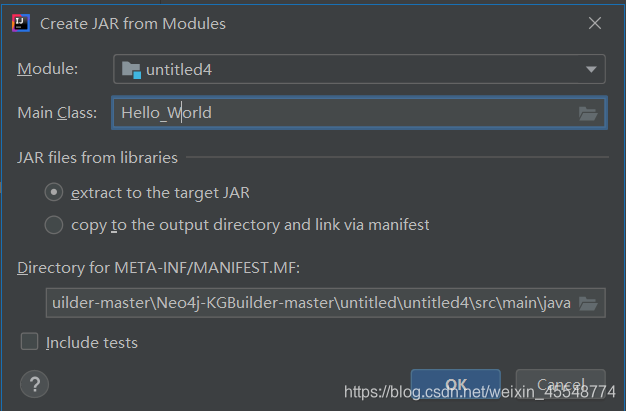
点击build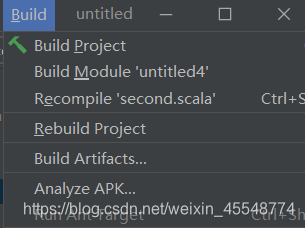
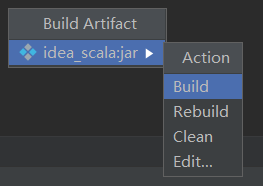
产生对应jar包
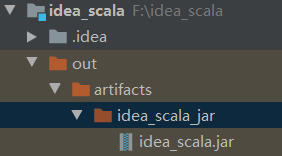
至此就完成了通过IDEA手动生成jar包的过程
手动提交到spark集群上执行
首先将生成jar复制下来,通过下面这条命令传入到集群中
docker cp C:\Users\Administrator\Desktop\untitled2.jar master:/opt
之后启动spark集群,进入到/opt目录下
使用如下命令运行jar包,Hello_World是主类的名称
spark-submit --class Hello_World --master yarn untitled2.jar
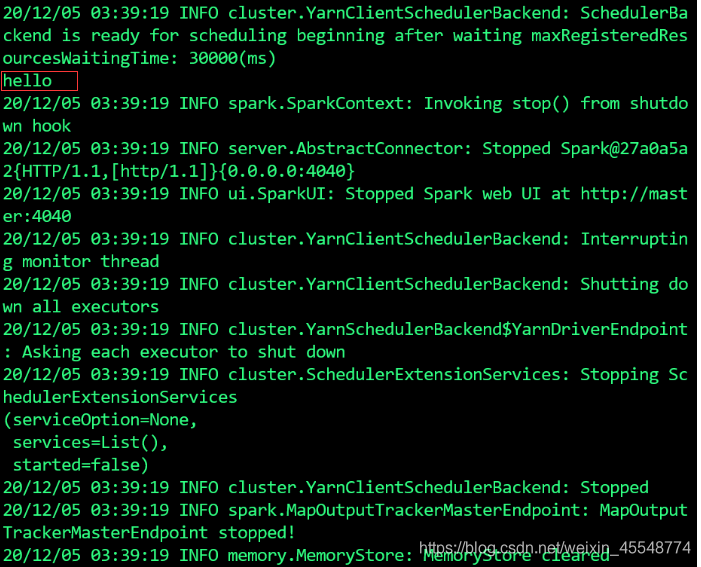
至此就完成了整个的流程
Windows中使用IDEA写程序,自动提交到docker搭建的spark集群上运行
1 搭建IDEA环境,这里和上面的内容相同,不再赘述
2 启动本机docker中的spark环境
start-all.sh
start-dfs.sh
start-yarn.sh
3 创建一个scala类,写入下面的示例代码
/**
* Created by zf on 12/3/20.
*/
import scala.math.random
import org.apache.spark._
/** Computes an approximation to pi */
object SparkPi2 {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Spark Pi").set("spark.executor.memory", "512m")
.set("spark.driver.host","10.0.75.1")//这个ip很重要,我因为这个ip没有设置正确卡了好长时间,我使用的是docker,这个ip就要设置为本机在docker分配的虚拟网卡中的ip地址,如果设置成其他网卡的ip会被主机拒绝访问
.set("spark.driver.cores","1")
.setMaster("spark://127.0.0.1:7077") //这里应设为master的ip加上配置spark时设置的端口,一般都为7077,头面的是windows本机的ip或者直接使用127.0.0.1
.setJars(List("D:\\edge文件下载位置\\Neo4j-KGBuilder-master\\Neo4j-KGBuilder-master\\untitled\\untitled2\\out\\artifacts\\untitled2_jar\\untitled2.jar"))
//这里是jar包存放的位置
val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
val n = 100000 * slices
val count = spark.parallelize(1 to n, slices).map {
i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x * x + y * y < 1) 1 else 0
}.reduce(_ + _)
println("Pi is roughly " + 4.0 * count / n)
spark.stop()
}
}
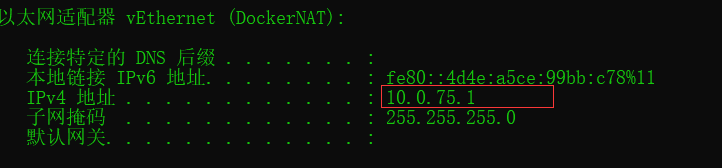
.set("spark.driver.host","10.0.75.1")
这里的10.0.75.1可以在cmd中使用ipconfig在下面找到,注意必须是这个ip地址
4 极有可能出现的错误:
1 如果出现spark运行报错:check your cluster UI to ensure that workers are registered and have sufficient resources,那证明你的spark集群上内存不够了,需要添加内存。
找到spark-env.sh文件,查看配置,看看是不是内存容量设置的过小了,我最设置的是128m,过小导致运行出现了问题,后来改成了4G问题就解决了。
注意master和slave节点都要检查!!!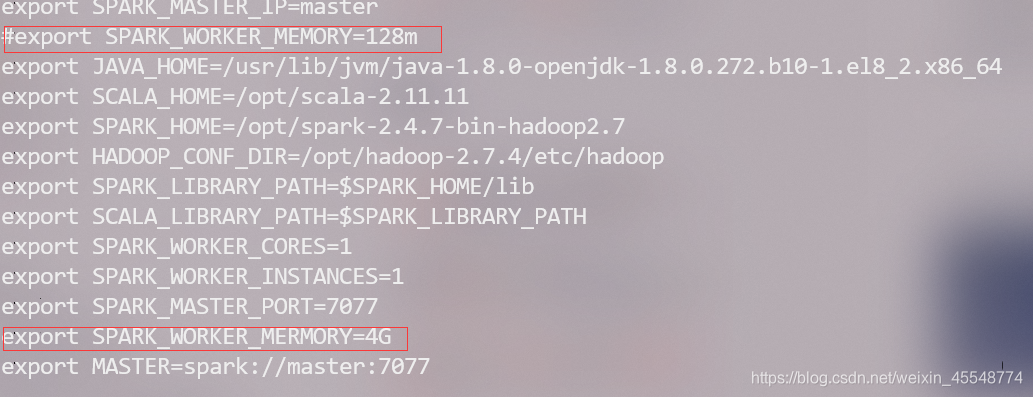
2 修改代码之后,最后都rebuild一下
此时一定要rebulid一下
都配置完成之后,运行程序就大功告成了
5自动运行程序结果
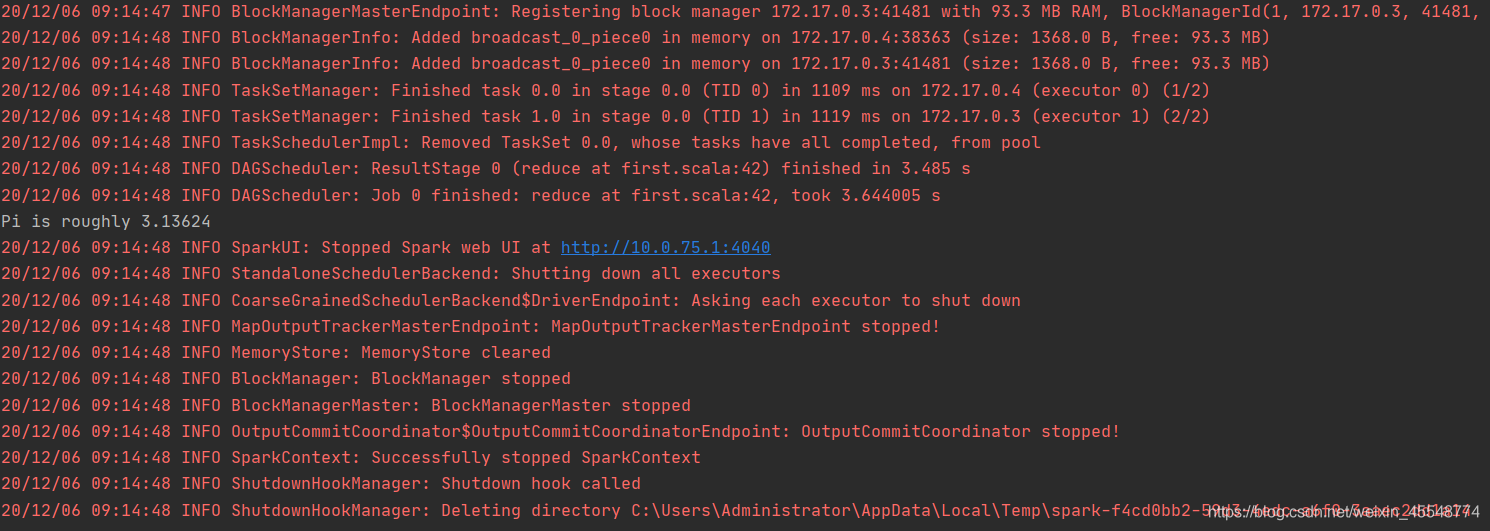
RDD编程初级实践
1 启动spark-shell
2 据给定的实验数据,在spark-shell中通过编程来计算题目内容
数据下载:
链接:https://pan.baidu.com/s/1lDnee9CxLKU31Zu5gFoIzw
提取码:6vzx
首先将数据加载到master中,使用
var rdd=sc.textFile("file:///usr/mydata/Data01.txt")
将数据对出,使用
rdd.collect
将数据打印出来查看
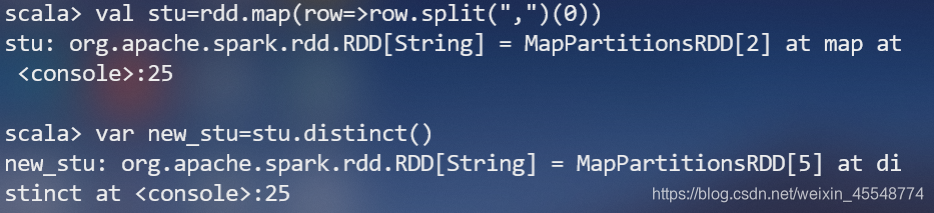
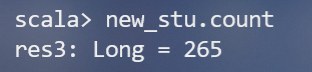
(1)该系总共有多少学生;(首先将数据按照“,”进行分割,由于一个学生可能选修多门课,所以还要对数据进行去重)
(2)该系共开设来多少门课程;
同第一问到的思路一样,取出课程进行去重处理之后进行统计即可。

(3)Tom同学的总成绩平均分是多少;

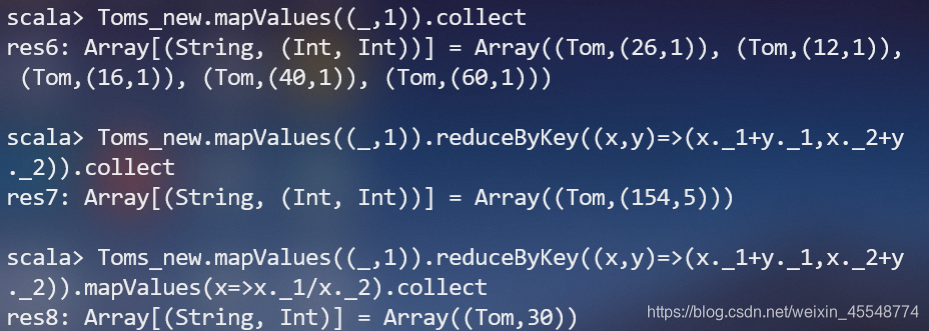
(4)求每名同学的选修的课程门数;
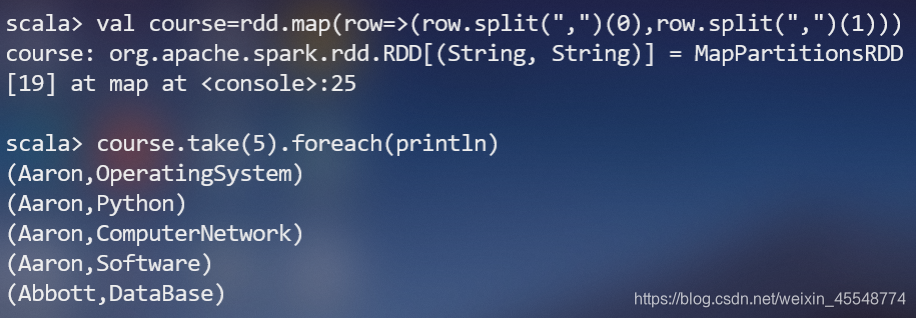

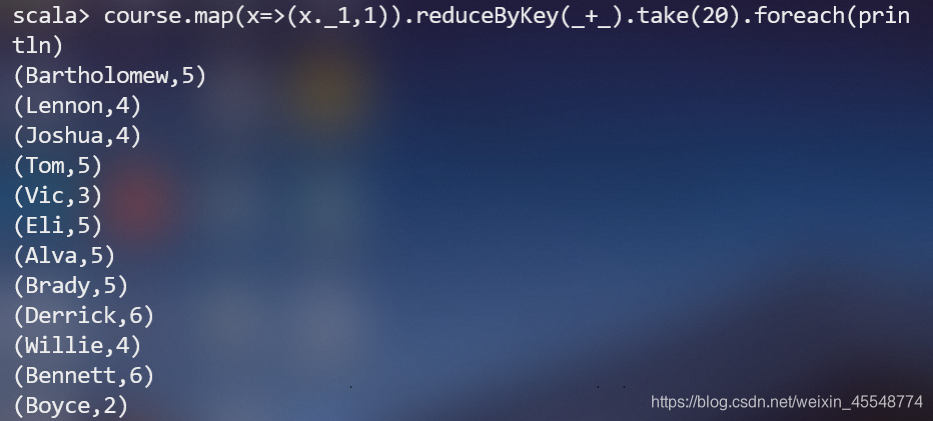
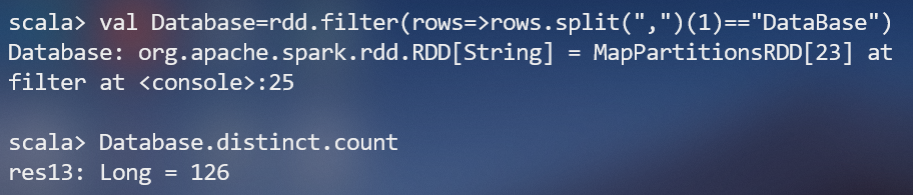
(5)该系DataBase课程共有多少人选修;
(6)各门课程的平均分是多少;

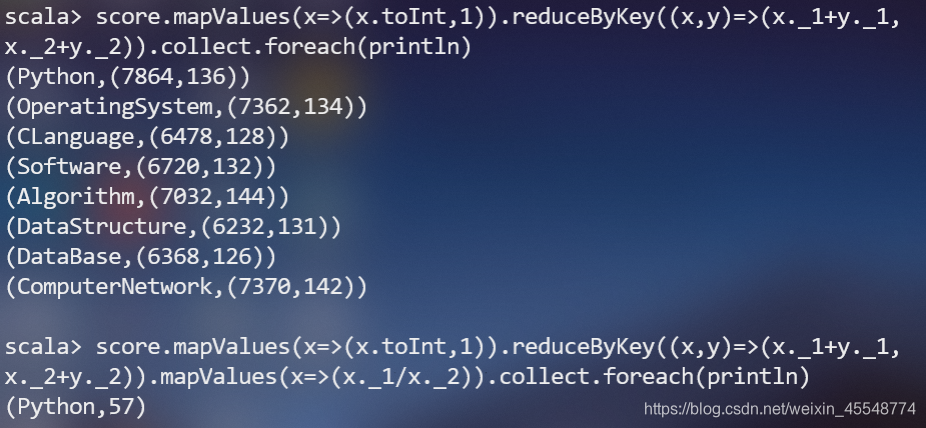

(7)使用累加器计算共有多少人选了DataBase这门课。


3 应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
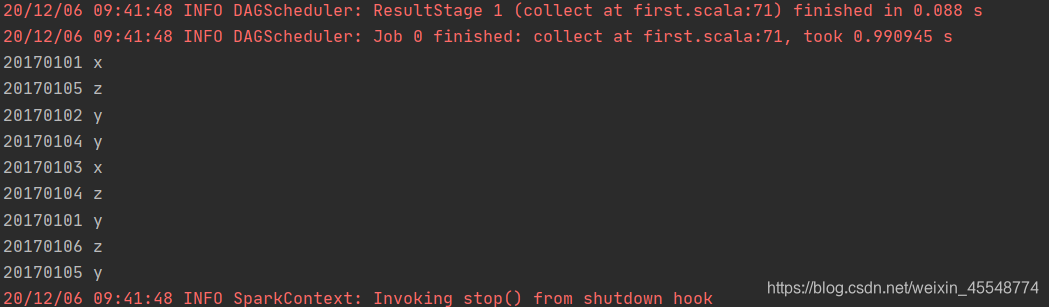
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
首先创建a.txt和b.txt,文件中输入上面对应的内容,最后将结果输入到文件C.txt中
代码如下(这里使用自动运行的方式)
import java.io.FileWriter
import java.net.InetAddress
import org.apache.spark._
object first {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("first").set("spark.executor.memory", "512m")
// .set("spark.driver.host", "10.0.75.1")
.set("spark.driver.cores", "2")
.setMaster("local") //spark://127.0.0.1:7077
.setJars(List("D:\\edge文件下载位置\\Neo4j-KGBuilder-master\\Neo4j-KGBuilder-master\\untitled\\untitled2\\out\\artifacts\\untitled2_jar\\untitled2.jar")) // maven打的jar包的路径
.set("spark.driver.allowMultipleContexts", "true")
// .set("spark.driver.port","50516")
val sc = new SparkContext(conf)
// 读取文件A
var A = sc.textFile("C:\\Users\\Administrator\\Desktop\\a.txt")
// 读取文件B
var B = sc.textFile("C:\\Users\\Administrator\\Desktop\\b.txt")
// 对文件A和B进行整合并去重
var C = (A ++ B).distinct
var results = C.collect()
// 将结果输出到C.txt中
val out = new FileWriter("C:\\Users\\Administrator\\Desktop\\C.txt",true)
for(item<-results){
out.write(item+"\n")
println(item)
}
out.close()
}
}
运行结果
4 应用程序实现平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
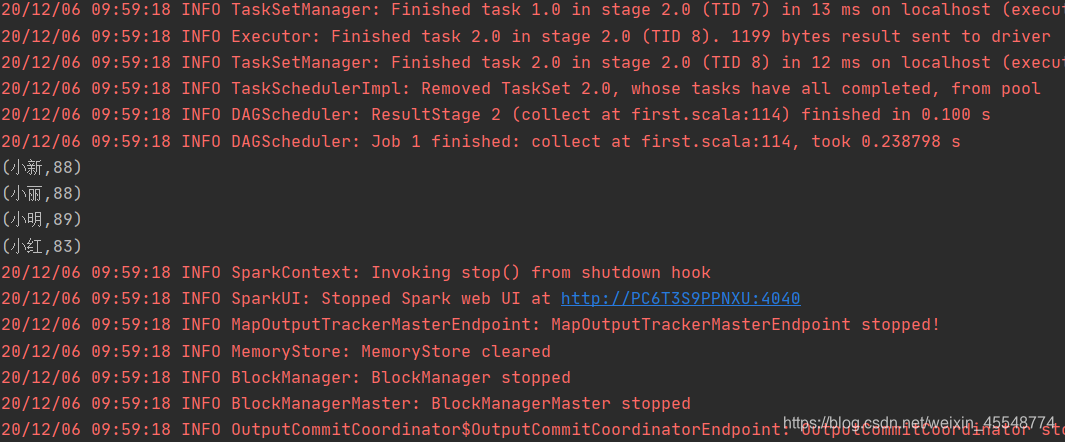
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
新建三个文件
将题目要求的数据输入到对应的文件夹中去(这里注意文件中的编码形式为utf-8)
代码如下(采用自动运行的方式):
import java.io.FileWriter
import java.net.InetAddress
import org.apache.spark._
object first {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("first").set("spark.executor.memory", "512m")
// .set("spark.driver.host", "10.0.75.1")
.set("spark.driver.cores", "2")
.setMaster("local") //spark://127.0.0.1:7077
.setJars(List("D:\\edge文件下载位置\\Neo4j-KGBuilder-master\\Neo4j-KGBuilder-master\\untitled\\untitled2\\out\\artifacts\\untitled2_jar\\untitled2.jar")) // maven打的jar包的路径
.set("spark.driver.allowMultipleContexts", "true")
// .set("spark.driver.port","50516")
val sc = new SparkContext(conf)
// 读取文件Algorithm.txt
var A = sc.textFile("C:\\Users\\Administrator\\Desktop\\Algorithm.txt")
// 读取文件Database.txt"
var B = sc.textFile("C:\\Users\\Administrator\\Desktop\\Database.txt")
// 读取文件Python.txt
var C = sc.textFile("C:\\Users\\Administrator\\Desktop\\Python.txt")
// 对三个文件进行整合
var all = A ++ B ++ C
print(all.collect)
// // 将每个名字作为键,值为一个键值对,该键值对的键为成绩,值为1(用于后面计算平均值计数用)
val student_grade = all.map(row=>(row.split(" ")(0),(row.split(" ")(1).toInt,1)))
// 对上述RDD做聚合,值的聚合返回一个二元组,第一个元素是该学生所有课的成绩求和,第二个元素是该学生选修课的数目,然后再做一个映射
// 将人名作为第一个元素,所有课的总成绩除以选修课程的数目得到该学生的平均成绩作为第二个元素
val student_ave = student_grade.reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).map(x=>(x._1,x._2._1/x._2._2))
var results = student_ave.collect
// 将结果输出到output.txt中
val out = new FileWriter("C:\\Users\\Administrator\\Desktop\\result.txt",true)
for(item<-results){
out.write(item+"\n")
println(item)
}
out.close()
}
}
运行结果
5 采用手动打包上传集群的方式实现2的内容
首先建立a.txt和b.txt,将其上传到hdfs上
hadoop fs -put /opt/spark/b.txt /
hadoop fs -put /opt/spark/a.txt /
代码如下:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
import java.io._
object first {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("first")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
val A = sc.textFile("/a.txt")
// 读取文件B
val B = sc.textFile("/b.txt")
//val data = sc.textFile(dataFile,2)
val c = (A ++ B).distinct
val da = c.distinct()
da.coalesce(1,true).saveAsTextFile("/result")
//da.saveAsTextFile("file:///opt/spark/c.txt")
val res=da.collect()
for(item<-res) {
println(item)
}
}
}
将代码打成jar包上传到集群中
docker cp C:\Users\Administrator\Desktop\untitled2.jar master:/opt
之后运行程序
spark-submit --class first --master yarn-client untitled2.jar
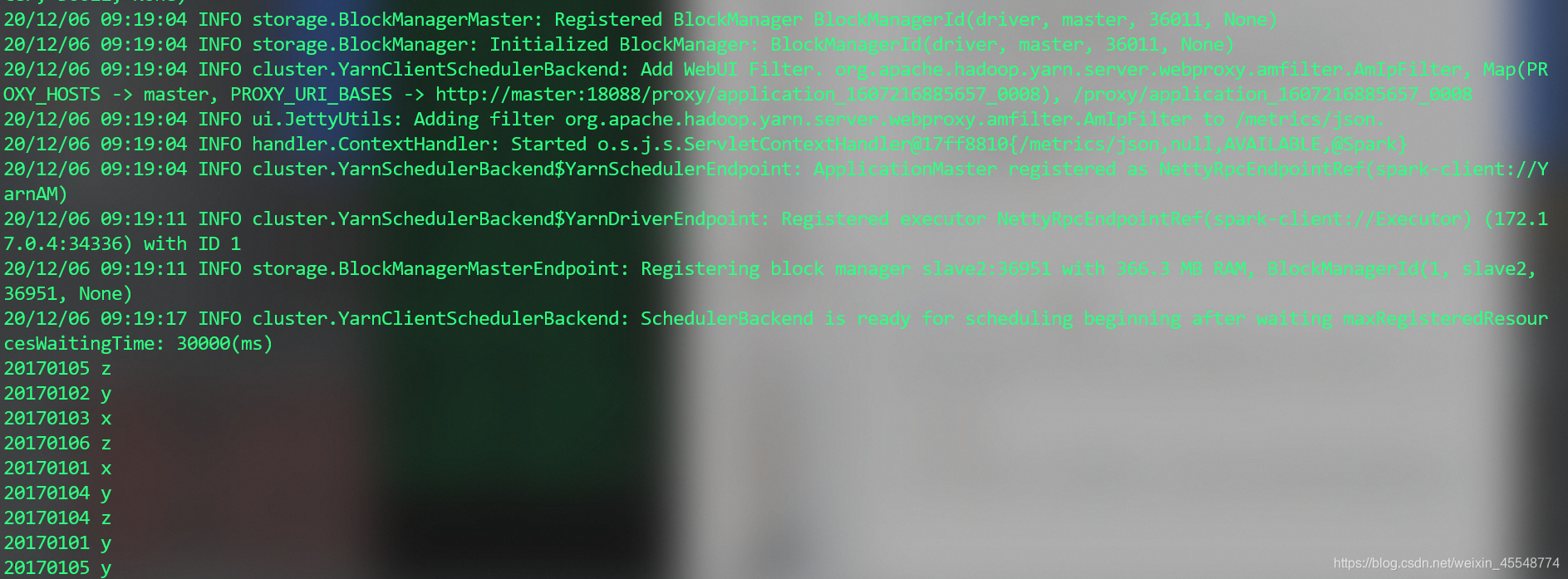
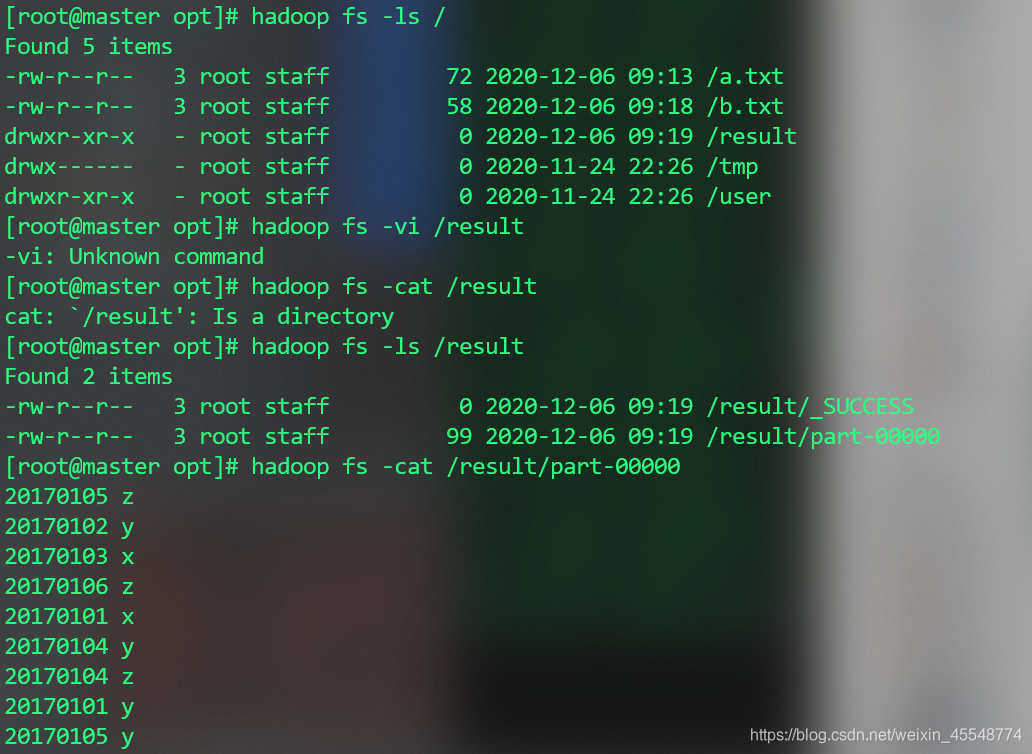
查看运行结果
由于写的比较匆忙,内容比较多,其中可能出现以下小问题,欢迎大家批评指正!
来源:oschina
链接:https://my.oschina.net/u/4323713/blog/4780825