Zilliz 公司以 “重新定义数据科学” (Reinvent Data Science)为愿景,专注于研发利用新一代异构计算的开源数据科学软件。随着各项目的蓬勃发展,我们对于持续集成、持续交付、持续部署(CI/CD)都提出了更高的要求。本文是 CI/CD 系列的开篇,重点介绍持续集成的编译优化实践。
| 问题与挑战
在编译构建过程中我们遇到以下几个问题:
1) 编译时间较长
项目每天都要完成上百次的代码集成,面对几十万行的代码量,开发人员进行小的 feature 改动都有可能会导致工程的全量编译,需要花费超过一个小时或者更长时间,显然让人难以接受。
2) 编译环境复杂
项目代码在不同的操作系统(CentOS、Ubuntu 等)、底层依赖库(GCC、LLVM、CUDA 等)、硬件架构等环境下进行编译,并且各编译环境下生成的编译产物都很有可能无法在其他平台下使用。
3) 项目依赖关系复杂
当前项目编译所涉及的各功能组件依赖以及第三方依赖不下三四十个,项目发展时常带来依赖关系的变动,难免会遇到依赖冲突问题。依赖之间的版本控制过于复杂,更新依赖版本容易导致影响其他组件业务。
4) 第三方依赖下载缓慢或无法下载
网络延迟或者第三方依赖仓库不稳定等问题所导致资源下载缓慢或访问失败,严重影响代码集成构建。
| 主要思路
对项目的依赖关系进行解耦。将依赖关系复杂的组件进行拆分,通过不同的仓库进行版本管理,以配置文件的形式来组织各组件的版本信息、编译选项、依赖关系等信息。配置文件加入到组件仓库进行版本管理,随着项目迭代进行更新。
实现组件间的编译优化。根据配置文件所记录的依赖关系、编译选项等信息去拉取相关组件代码进行编译,编译后生成的二进制产物以及对应编译产物的归档清单进行统一标记打包,上传到私有仓库进行集中存储。在组件以及该组件所依赖的其他组件未发生改动时,通过归档清单对编译产物进行回放,起到了编译缓存效果。网络延迟或者第三方依赖仓库不稳定等问题,可通过在内部搭建私有化仓库或者使用多镜像仓库去解决。
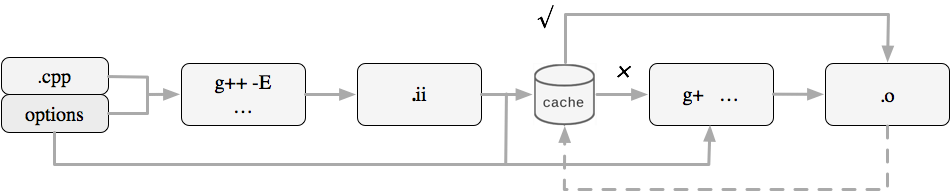
实现组件内部的编译优化。选择针对于特定语言的编译缓存工具,将编译过程中的编译产物进行缓存并打包上传到私有仓库进行集中存储。举个例子,就 C/C++ 编译而言,可以选择 CCache 这类编译缓存工具来缓存 C/C++ 编译的中间产物,编译完成后对 CCache 本地缓存进行归档上传。诸如此类的编译缓存工具只是对发生改动的代码文件进行编译后逐一缓存,对未发生变动的代码文件命中对应的编译产物进行拷贝,使得它可以直接参与到最终编译。
保证编译环境一致性。由于编译产物的生成对于系统环境变化较为敏感,在不同的操作系统、底层依赖库等环境下都可能会出现未知的错误,因此我们需要根据系统环境变化对编译产物缓存进行标记归档。我们所接触的系统环境千差万别,很难通过某几个维度对其进行归类,因此我们引入了容器化技术,统一编译环境,从而解决这类问题。
| 实施关键点
-
项目依赖关系解耦
对于项目依赖关系的解耦,并没有一个统一的定义。项目内部依赖关系通常是根据业务需求、技术栈选型、部署方式等方面去考虑的。项目外部依赖关系通常是根据第三方依赖库与内部组件的依赖性来确定的。在组件间存在编译方式、编译选项等方面有强依赖关系的第三方依赖库,选择连同组件业务代码一起编译。对项目中能够共用的第三方依赖库,形成统一的独立仓库进行集中编译。
-
组件间编译优化
对于组件间的工程编译优化分为以下工作:
1. 开发人员提交修改的组件业务代码触发项目的代码集成,获取该组件仓库中的配置文件,根据依赖关系获取上下游依赖组件的版本信息(Git Branch or Tag、Git Commit ID)和编译选项等信息,构建依赖关系图。
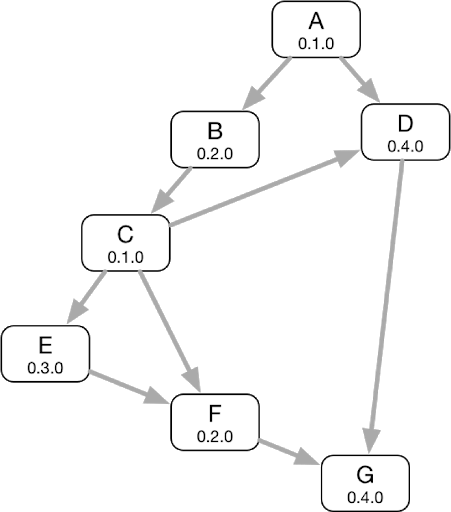
2. 依赖关系检查。针对组件之间出现的循环依赖、版本冲突等问题进行报警。
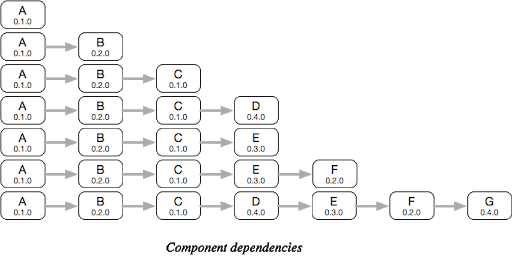
3. 依赖关系扁平化处理。依赖关系图进行深度优先遍历(DFS)排序,重复依赖的组件实现前置合并。

4. 对每个组件的版本信息、编译选项等信息生成一个哈希值,再通过 MerkleTree 算法生成包含有该组件依赖关系的加密哈希值(Root Hash),该加密哈希值与组件名称等信息组合成为该组件的唯一标签信息。
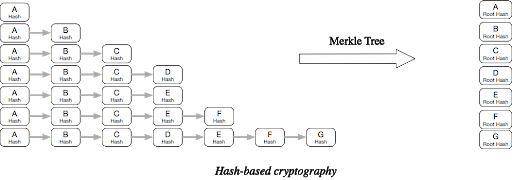

5. 根据组件的唯一标签信息去检查私有仓库是否存在该组件的编译产物归档文件。如果命中已存在的编译产物归档文件,则解压编译产物归档文件,获取归档清单文件进行编译产物的回放;如未命中,则对组件进行编译,生成的编译产物和清单文件进行标记归档并上传至私有仓库。
-
组件内部编译优化
对于组件内部的工程编译优化分为以下工作:
1. 将编译组件代码所需系统环境依赖加入到 Dockerfile。通过 Hadolint 工具对 Dockerfile 进行合规检查,确保镜像符合 Docker 的最佳实践。
2. 根据项目迭代版本号(项目版本号 + 构建版本号)、操作系统等版本信息进行编译环境镜像的构建。
3. 通过镜像启动用于构建编译环境的容器,并将镜像 ID 通过环境变量的形式传入到容器中。获取镜像 ID 命令如 “ docker inspect '--type=image' --format '{{.ID}}' repository/build-env:v0.1-centos7 ”。
4. 针对技术栈选择合适的编译缓存工具对代码进行编译缓存。进入到容器内部进行代码集成与编译,根据镜像 ID 去检查私有仓库是否存在针对于编译缓存工具的编译缓存。如果命中已存在的编译缓存,则直接下载并解压到指定目录。编译环境下的所有组件都编译完成后,再将编译缓存工具生成的编译缓存通过项目迭代版本号、镜像 ID 等信息统一标记打包并更新上传至私有仓库。
-
构建方案再优化
最初我们构建的镜像体积过于臃肿,增加了磁盘和网络资源开销,还使得部署时间越来越长。对此我们有以下几点建议:
1. 选择最精简的基础镜像来降低镜像体积,如:alpine、busybox 等。
2. 减少镜像层数。所需的环境依赖尽量做到能够复用。合并指令,可以用 "&&" 将多条命令连接起来。
3. 清理镜像构建的中间产物。
4. 充分利用镜像缓存构建。
方案实施一段时间后,随着编译缓存增加导致私有化仓库的磁盘和网络资源开销加大,并且部分编译缓存利用率不高。对此我们有以下几点建议:
1. 定期清理缓存文件。通过脚本等形式对私有化仓库进行定期检查,对于一段时间未发生变动且下载量不高的缓存文件进行清理。
2. 有选择的进行编译缓存。对于编译所需资源开销较小的代码,可不进行编译缓存。
由于 Docker 的安装与使用、私有化仓库搭建等内容不在本章讨论的范畴,感兴趣的同学可以自行研究。
| 总结与展望
本文从自身项目依赖关系出发进行分析,详细介绍了组件间与组件内部的编译优化方法,并提供了构建稳定高效的代码持续集成系统的思路与最佳实践方案。解决了依赖关系复杂所带来的项目迭代缓慢问题,统一在容器内部操作以保证环境的一致性,通过对编译产物的回放以及编译缓存工具的缓存来提升编译效率。
目前该实践方案已在 Milvus 等产品的持续集成中提供相应的技术支持。采用了本文所描述的工作进行编译优化后,项目工程的编译时间平均减少了 60%,极大地提升了项目构建效率。后续我们会对于组件间与组件内部的编译并行化进行探究,持续为数据科学领域的发展进行赋能。
| 欢迎加入 Milvus 社区
github.com/milvus-io/milvus | 源码
milvus.io | 官网
milvusio.slack.com | Slack 社区
zhihu.com/org/zilliz-11/columns | 知乎
zilliz.blog.csdn.net | CSDN 博客
space.bilibili.com/478166626 | Bilibili

来源:oschina
链接:https://my.oschina.net/u/4209276/blog/4299935