threadpool模型:
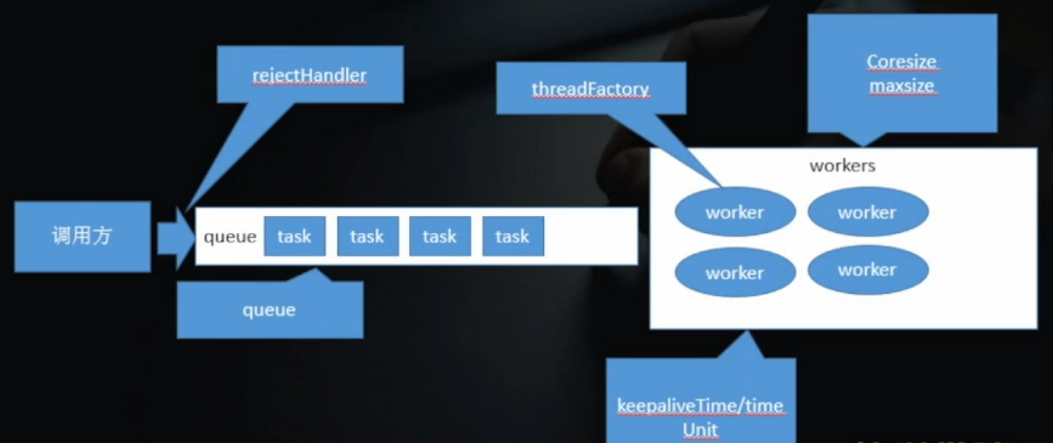
调用方通过调用api将任务,装进queue里,然后会有一个机制监事queue里有没有task,如果有task,就分配给某个worker去执行。workers代表线程池的话.worker就是某条线程了。
线程池的构造方法:
Executor框架最核心的类是ThreadPoolExecutor,他是线程池的实现类,主要由下列7个组件构成。
package java.util.concurrent;
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}int corePoolSize, // 线程池可使用线程数的最小值
int maximumPoolSize, // 线程池容量的最大值
maximumPoolSize:是一个静态变量,在变量初始化的时候,有构造函数指定.
long keepAliveTime, // 当线程池中的线程数大于corePoolSize时,keepAliveTime为多余的空闲线程等待新任务的最长时间,超过这个时间后多余的线程将被终止。这里把keepAliveTime设置为0L,意味着多余的空闲线程会被立即终止。
TimeUnit unit, // 线程的阻塞时间单位,它的执行方法是TimeUnit.unit.Sleep(keepAliveTime);
内部调用了Thread.sleep()方法。但是它和Thread.sleep()方法的区别是,Thread.Sleep只能设置毫秒数,而TimeUnit.unit.Sleep()中的unit可以换成时间单位,比如DAYS、HOURS、MINUTES,SECONDS、MILLISECONDS和NANOSECONDS。
TimeUnit.MINUTES.sleep(4); // sleeping for 4 minutesBlockingQueue<Runnable> workQueue, // 阻塞队列,里面是Runnable类型,线程的任务
ThreadFactory threadFactory, // 创建线程,并为线程指定queue里面的runnable,线程池的构造方法,支持自定义threadFactory传入,我们可以自己编写newThread()方法,来实现自定义的线程创建逻辑。
public interface ThreadFactory {
Thread newThread(Runnable r);
}
RejectedExecutionHandler handler // 当ThreadPoolExecutor已经关闭或ThreadPoolExecutor已经饱和时(达到了最大线程池大小且工作队列已满),execute()方法将要调用的Handler。
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}并且这些成员变量,都是volatile修饰的
private volatile ThreadFactory threadFactory;
private volatile RejectedExecutionHandler handler;
private volatile long keepAliveTime;
private volatile boolean allowCoreThreadTimeOut;
private volatile int corePoolSize;
private volatile int maximumPoolSize;线程池成员属性和api方法介绍
largestPoolSize: 是一个动态变量,是记录线程曾经达到的最高值,也就是 largestPoolSize<= maximumPoolSize.
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
public int getLargestPoolSize() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
return largestPoolSize;
} finally {
mainLock.unlock();
}
}completedtaskcount:
返回已完成执行的近似任务总数。因为在计算期间任务和线程的状态可能动态改变,所以返回值只是一个近似值,但是该值在整个连续调用过程中不会减少。
当一个线程在workers容器中,准备remove时,线程会将自己的completedtaskcount赋值给线程池的completedtaskcount。
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
tryTerminate();
int c = ctl.get();
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
} public long getCompletedTaskCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
long n = completedTaskCount;
for (Worker w : workers)
n += w.completedTasks;
return n;
} finally {
mainLock.unlock();
}
}TaskCount 线程池执行的总任务数,包括已经执行完的任务数和任务队列中目前还需要执行的任务数
public long getTaskCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
long n = completedTaskCount;
for (Worker w : workers) {
n += w.completedTasks;
if (w.isLocked())
++n;
}
return n + workQueue.size();
} finally {
mainLock.unlock();
}
}getActiveCount();Thread.activeCount() 得到是存活的线程数 返回值是int类型
public int getActiveCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int n = 0;
for (Worker w : workers)
if (w.isLocked())
++n;
return n;
} finally {
mainLock.unlock();
}
}常见线程池类型:
singletenthreadPool:
SingleThreadExecutor是使用单个worker线程的Executor。下面是SingleThreadExecutor的源代码实现。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}SingleThreadExecutor的corePoolSize和maximumPoolSize被设置为1。其他参数与FixedThreadPool相同。SingleThreadExecutor使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Integer.MAX_VALUE)。SingleThreadExecutor使用无界队列作为工作队列对线程池带来的影响与FixedThreadPool相同,这里就不赘述了。
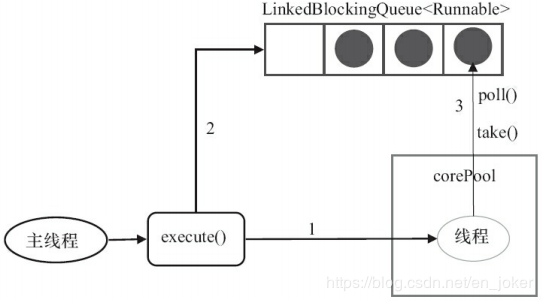
- 如果当前运行的线程数少于corePoolSize(即线程池中无运行的线程),则创建一个新线程来执行任务。
- 在线程池完成预热之后(当前线程池中有一个运行的线程),将任务加入LinkedBlockingQueue。
- 线程执行完1中的任务后,会在一个无限循环中反复从LinkedBlockingQueue获取任务来执行。
fixedthreadpool:
package java.util.concurrent;
public class Executors {
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
}FixedThreadPool的corePoolSize和maximumPoolSize都被设置为创建FixedThreadPool时指定的参数nThreads。
当线程池中的线程数大于corePoolSize时,keepAliveTime为多余的空闲线程等待新任务的最长时间,超过这个时间后多余的线程将被终止。这里把keepAliveTime设置为0L,意味着多余的空闲线程会被立即终止。
FixedThreadPool的execute()方法的运行示意图如下所示。
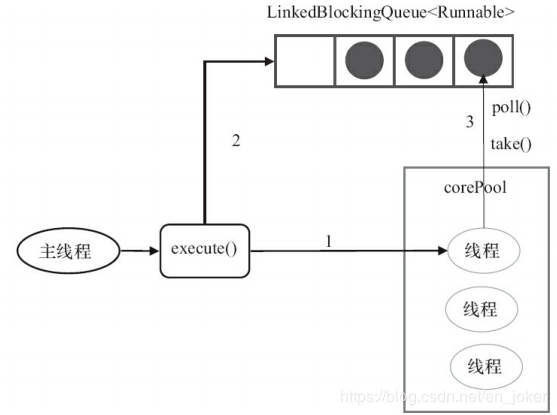
对上图的说明如下。
- 如果当前运行得线程数少于corePoolSize,则创建线程来执行任务。
- 在线程池完成预热之后(当前运行的线程数等于corePoolSize),将任务加入LinkedBlockingQueue。
- 线程执行完1中的任务后,会在循环中反复从LinkedBlockingQueue获取任务来执行。
FixedThreadPool使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Integer.MAX_VALUE)。使用无界队列作为工作队列会对线程池带来如下影响。
- 当线程池中的线程数达到corePoolSize后,新任务将在无界队列中等待,因此线程池中的线程数不会超过corePoolSize。
- 由于1,使用无界队列时maximumPoolSize将是一个无效参数。
- 由于1和2,使用无界队列时keepAliveTime将是一个无效参数。
- 由于使用无界队列,运行中的FixedThreadPool(未执行方法shutdown()或shutdownNow())不会拒绝任务(不会调用RejectedExecutionHandler.rejectedExecution方法)。
cachethreadpool:
CacheThreadPool是一个会根据需要创建新线程的线程池。下面是创建CacheThreadPool的源代码。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}CacheThreadPool的corePoolSize被设置为0,即corePool为空;maximumPoolSize被设置为Integer.MAX_VALUE,即maximumPool是无界的。这里把keepAliveTime设置为60L,意味着CacheThreadPool中的空闲线程等待新任务的最长时间为60秒,空闲线程超过60秒后将会被终止。
FixedThreadPool和SingleThreadExecutor使用无界队列LinkedBlockingQueue作为线程池的工作队列。CacheThreadPool使用没有容量的SynchronousQueue作为线程池的工作队列,但CacheThreadPool的maximumPool是无界的。这意味着,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,CacheThreadPool会不断创建新线程。极端情况下,CacheThreadPool会因为创建过多线程而耗尽CPU和内存资源。
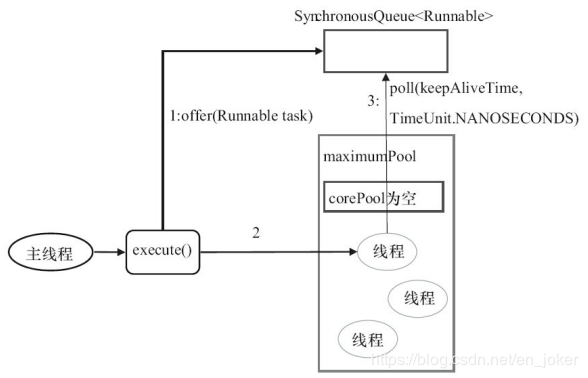
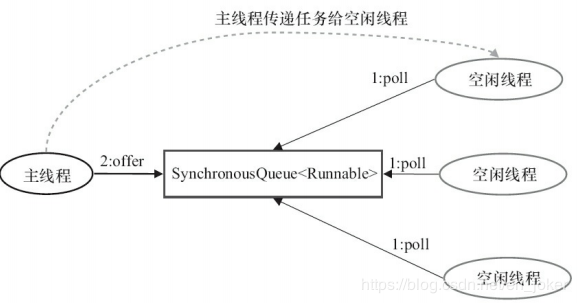
对上图的说明如下。
- 首先执行SynchronousQueue.offer(Runnable task)。如果当前maximumPool中有空闲线程正在执行SynchronousQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS),那么主线程执行offer操作与空闲线程执行的poll操作配对成功,主线程把任务交给空闲线程执行,execute()方法执行完成;否则执行下面的步骤2。
- 当初始maximumPool为空,或者maximumPool中当前没有空闲线程时,将没有线程执行SynchronousQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)。这种情况下,步骤1将失败。此时CachedThreadPool会创建一个新线程执行任务,execute()方法执行完成。
- 在步骤2中新创建的线程将任务执行完后,会执行SynchronousQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)。这个poll操作会让空闲线程最多在SynchronousQueue中等待60秒钟。如果60秒钟内主线程提交了一个新任务(主线程执行步骤1),那么这个空闲线程将执行主线程提交的新任务;否则,这个空闲线程将终止。由于空闲60秒的空闲线程会被终止,因此长时间保持空闲的CachedThreadPool不会使用任务资源。
前面提到过,SynchronousQueue是一个没有容量的阻塞队列。每个插入操作必须等待另一个线程的对应移除操作,反之亦然。CachedThreadPool使用SynchronousQueue,把主线程提交的任务传递给空闲线程执行。CachedThreadPool中任务传递的示意图如下所示。
ScheduledThreadPool
执行定时任务的线程池
创建线程池的四种方式
这四种方式,都实现了RejectedExecutionHandler接口
Abortpolicy
会抛出异常,导致当前线程退出
当我们创建线程池时,不指定rejectedExecutionHandler时,就会默认使用AbortPolicy,当我们通过executor.execute(runnable)任务时,可能会发生异常,并将异常直接返回给了调用者。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}CallerRunsPolicy
当线程池的存活线程数,达到了最大值,此时又有新的请求过来,线程池会调用rejectedExecutionHandler这个接口的实现类的rejectedExecution的方法,此时该实现类正好是CallerRunsPolicy,它会让新请求,在自己的线程上执行run方法,如果run方法消耗时间长,它会阻塞web容器的请求,影响web容器处理其他请求的性能。
当有外部请求访问web服务端时,tomcat会分配一条线程(tomcat默认有150个线程,可以配置最大的为1500个线程来接收处理请求,且这些线程之间具有隔离性不会互相影响对方)来处理这个请求,当这个请求要用到线程池,且我们的线程池是基于CallerRunsPolicy来创建的,那么CallerRunsPolicy会,使用当前请求的线程,来执行run方法。而当这个run方法执行时间过长时,tomcat的请求就会被占用不放,导致无法拿出空闲的线程去处理其他请求,就会影响到服务端的性能。
应用场景:当我们希望线程池满了之后,进行阻塞,就使用CallerRunsPolicy,阻塞的是调用方的,不会往queue里放任务了。
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}看上面的rejectedExecution方法体,很有意思,它执行线程的方式,是r.run()而不是start()方法,这很耐人寻味,原因有两个
我们在main方法中,准备启动一个线程时,如果在代码中我们使用thread.star()方法,jvm在执行到这行时,实际上会创建一个新的线程,来执行线程对象中的run方法,此时在执行run方法的线程,与执行main方法的线程,是两条线程,没有关联。而上面调用了runnable接口实例的run方法,jvm在执行时,根本不会创建新线程去执行,而是就在当前的请求(线程)里之心run方法,此时的run方法,根本不需要开辟或分配新线程来运行,而是当做一个普通方法来执行了。所以此时run方法卡住了,他就会卡住当前的请求,就会卡住web容器的请求。影响web容器处理其他请求的性能。
DiscardOldestPolicy 在我的队列里面,踢出出最老的一个任务
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}DiscardPolicy
不做任何处理
ThreadPool的三个阶段
Workers容器
0<active<coresize
当一个task准备分配给workers容器,希望调用一个线程去执行它时,如果此时容器中存活的线程数小于coresize指定线程数时,会一次性创建一条新线程来执行任务,而且新线程也会驻留在内存中。而当线程执行完任务,并不会收回,而是变成等待状态了。
问题:什么时候出现activesize会超过coresize?
当coreSize向maxsize变迁的时候,不是由workers决定的,而是由queue决定的。queue里面的task数量达到最大值的时候,coreSize就会向maxsize变迁了。我们在创建线程池的时候。线程池的构造方法会有一个BlockingQueue<Runnable> workQueue,然后我们初始化线程池时会指定这个queue的size,那么调用者一边往queue里装task,task也会一边分配给workers去执行。只有当queue里面的任务数,size达到了设置的最大size时,wokers才会去创建更多的线程,来处理任务,创建新线程的数量,不能超过maxsize。
core<active<maxsize
条件:任务queue满了,会新创建线程去处理任务
active == maxsize
跟rejectHandlerPolicy有关系,配置了CallerRunsPolicy就会阻塞请求方,拒绝接受任务;配置了abortPolicy就会返回异常,意思是线程数已经创够了,不能继续创建了;配置了discardOldPolicy就会删除最老任务,配置了discardPolicy就什么都不做。
本文章参考了:https://blog.csdn.net/en_joker/article/details/84973420 《并发:ThreadPoolExecutor详解》
来源:oschina
链接:https://my.oschina.net/u/3156785/blog/3036672