 requests.request(method,url,**kwargs)
requests.request(method,url,**kwargs)

- method:请求方式,对应get/put/post等7种;
r = requests.request('GET',url,**kwargs)
r = requests.request('HEAD',url,**kwargs)
......
- url:拟获取页面的url链接;
- **kwargs:控制访问的参数,共13个;均为可选项
- params : 字典或字节序列,作为参数增加到url中;
- data : 字典、字节序列或文件对象,作为Request的内容
- json : JSON格式的数据,作为Request的内容;
- headers :字典,HTTP定制头;
- cookies :字典或CookieJar、Request中的cookie;
- auth:元组,支持HTTP认证功能;
- files : 字典类型,传输文件;
- timeout :设定超时时间,秒为单位;
- proxies : 字典类型,设定访问代理服务器,可以增加登录认证;
- allow_redirects : True/False,默认为True,重定向开关;
- stream: True/False,默认为True,获取内容立即下载开关;
- verify : True/False,默认为True,认证SSL证书开关;
- cert : 本地SSL证书路径;
requests.get(url,params = None,**kwargs) requests.head(url,**kwargs) requests.post(url,data = None,params = None,**kwargs) requests.put(url,data = None,**kwargs) requests.patch(url,data = None,**kwargs) requests.delete(url,**kwargs) requests.get(url,params = None,**kwargs)
url : 拟获取页面的url链接;
params :url中的额外参数,字典或字节流格式,可选;
**kwargs :12个控制访问的参数;
r = requests.get(url)
Response对象包含爬虫返回的内容。
Response对象的属性:


理解Request库的异常:


r.raise_for_status() 如果不是200,产生异常 requests.HTTPError
HTTP(Hypertext Transfer Protocol)协议:超文本传输协议。
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议;
HTTP协议采用URL作为定位网络资源的标识,URL格式如下:
host : 合法的Internet主机域名或IP地址;
port : 端口号,缺省端口为80;
path : 请求资源的路径。
HTTP协议对资源的操作:
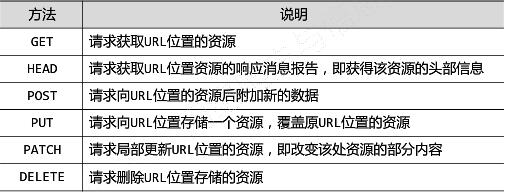

通过URL和命令管理资源,操作无独立状态,网络通道及服务器成为了黑盒子。
理解PATCH和PUT的区别:
假设URL位置有一组数据UserID、UserName等20个字段。
需求:用户修改了UserName,其他不变。
采用PATCH,仅向URL提交UserName的局部更新请求;
采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除。
PATCH最主要的好处:节省网络带宽。
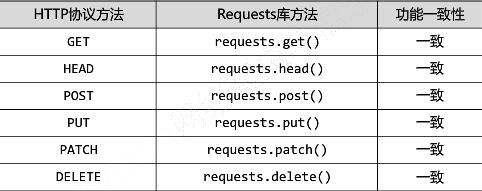
HTTP协议与Requests库:

实例1:京东商品页面的爬取。
网址:http://item.jd.com/2967929.html
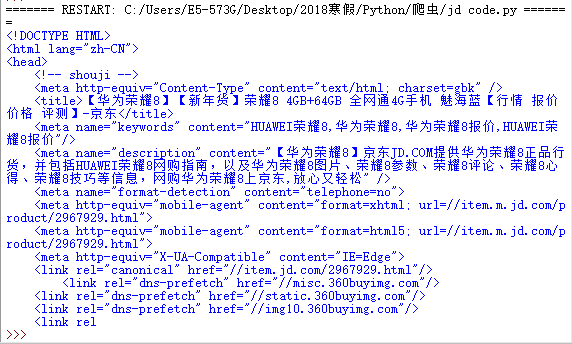
>>> import requests>>> r = requests.get("http://item.jd.com/2967929.html")>>> r.status_code200>>> r.encoding'gbk'>>> r.text[:1000]'<!DOCTYPE HTML>\n<html lang="zh-CN">\n<head>\n <!-- shouji -->\n <meta http-equiv="Content-Type" content="text/html; charset=gbk" />\n <title>【华为荣耀8】【新年货】荣耀8 4GB+64GB 全网通4G手机 魅海蓝【行情 报价 价格 评测】-京东</title>\n <meta name="keywords" content="HUAWEI荣耀8,华为荣耀8,华为荣耀8报价,HUAWEI荣耀8报价"/>\n <meta name="description" content="【华为荣耀8】京东JD.COM提供华为荣耀8正品行货,并包括HUAWEI荣耀8网购指南,以及华为荣耀8图片、荣耀8参数、荣耀8评论、荣耀8心得、荣耀8技巧等信息,网购华为荣耀8上京东,放心又轻松" />\n <meta name="format-detection" content="telephone=no">\n <meta http-equiv="mobile-agent" content="format=xhtml; url=//item.m.jd.com/product/2967929.html">\n <meta http-equiv="mobile-agent" content="format=html5; url=//item.m.jd.com/product/2967929.html">\n <meta http-equiv="X-UA-Compatible" content="IE=Edge">\n <link rel="canonical" href="//item.jd.com/2967929.html"/>\n <link rel="dns-prefetch" href="//misc.360buyimg.com"/>\n <link rel="dns-prefetch" href="//static.360buyimg.com"/>\n <link rel="dns-prefetch" href="//img10.360buyimg.com"/>\n <link rel'
全代码:
#jd code.pyimport requestsurl = "http://item.jd.com/2967929.html"try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding print(r.text[:1000])except: print("爬取失败")
运行结果:

限制是否能爬虫的两种方式:robots协议、判断http的头是否为浏览器;
实例2:亚马逊商品页面的爬取。
网址:http://www.amazon.cn/gp/product/B01M8L5Z3Y
>>> import requests #引入库>>> r = requests.get("http://www.amazon.cn/gp/product/B01M8L5Z3Y")>>> r.status_code #读取返回状态200>>> r.encoding #查看编码'UTF-8'>>> r.request.headers #读取http的头{'User-Agent': 'python-requests/2.18.4', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}>>> kv = {'user-agent':'Mozilla/5.0'} #构造键值对,模拟浏览器; #'Mozilla/5.0'是很标准的浏览器的身份标识字段>>> url = "http://www.amazon.cn/gp/product/B01M8L5Z3Y">>> r = requests.get(url,headers = {'user-agent':'Mozilla/5.0'}) #模拟浏览器访问网址>>> r.status_code200>>> r.request.headers #验证结果,头部被修改{'user-agent': 'Mozilla/5.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}>>> r.text[:1000]'\n\n\n\n\n\n\n\n \n \n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n \n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n \n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n \n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n <!doctype html><html class="a-no-js" data-19ax5a9jf="dingo">\n <head>\n<script type="text/javascript">var ue_t0=ue_t0||+new Date();</script>\n<script type="text/javascript">\n\nvar ue_hob=+new Date();\nvar ue_id=\'66XSFDDTW64FMKQK42YQ\',\nue_csm = window,\nue_err_chan = \'jserr-rw\',\nue = {};\n(function(d){var e=d.ue=d.ue||{},f=Date.now||function(){return+new Date};e.d=function(b){return f()-(b?0:d.ue_t0)};e.stub=function(b,a){if(!b[a]){var c=[];b[a]=function(){c.push([c.slice.call(arguments),e.d(),d.ue_id])};b[a].replay=function(b){for(var a;a=c.shift();)b(a[0],a[1],a[2])};b[a].isStub=1}};e.exec=function(b,a){return function(){if(1==window.ueinit)try{return b.apply(this,arguments)}catch(c){ueLogError(c,{attribution:a||"undefined",logLevel:"WARN"})}}}})(ue_csm);\n\nue.stub(ue,"log");ue.stub(ue,"onunload");ue.stub(ue,"onflush");\n\n(function(d,e){function h(f,b){if(!(a.ec>a.mxe)&&f){a.ter.pu'
全代码:
#amazon code.pyimport requestsurl = "http://www.amazon.cn/gp/product/B01M8L5Z3Y"try: kv = {'user-agent':'Mozilla/5.0'} r = requests.get(url,headers = kv) r.raise_for_status() r.encoding = r.apparent_encoding print(r.text[1000 : 2000])except: print("爬取失败")
实例3:百度网页爬取。
>>> import requests>>> kv = {'wd':'Python'}>>> r = requests.get("http://www.baidu.com/s",params = kv)>>> r.status_code200>>> r.request.url'http://www.baidu.com/s?wd=Python'>>> len(r.text)312484
全代码:
#baidu code.pyimport requestskeyword = "python"try: kv = {'wd':'Python'} r = requests.get("http://www.baidu.com/s",params = kv) print(r.request.url) r.raise_for_status() print(len(r.text))except: print("爬取失败")
实例4:360浏览器网页爬取。
>>> import requests>>> kv = {'q':'Python'}>>> r = requests.get("http://www.so.com/s",params = kv)>>> r.status_code200>>> r.request.url'https://www.so.com/s?q=Python'>>> len(r.text)275843
全代码:
#360 code.pyimport requestskeyword = "python"try: kv = {'q':'Python'} r = requests.get("http://www.so.com/s",params = kv) print(r.request.url) r.raise_for_status() print(len(r.text))except: print("爬取失败")
实例5:网络图片的爬取和存储。
图片地址:http://image.nationalgeographic.com.cn/2017/0211/20170211061910157.jpg
{kind=link}
代码:
#picture code.pyimport requestsimport osurl = "http://image.nationalgeographic.com.cn/2017/0211/20170211061910157.jpg"#root = "C:/Users/E5-573G/Desktop/2018寒假/python/爬虫/图" #正常运行,不会出错。绝对路径用/#root = "C:\Users\E5-573G\Desktop\2018寒假\Python\爬虫\图" 出现Unicode Error 错误,\转义的放式root = r"C:\Users\E5-573G\Desktop\2018寒假\Python\爬虫\图" #正常运行,不会出错。r\不需要转义path = root + url.split('/')[-1]try: if not os.path.exists(root): os.mkdir(root) if not os.path.exists(path): r = requests.get(url) with open(path,'wb') as f: f.write(r.content) f.close print("文件保存成功") else: print("文件已存在")except: print("爬取失败")
利用爬虫在淘宝网上查找“python web”向相关的商品:
#Crow TaobaoPrice.pyimport requestsimport re def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parsePage(ilt, html): try: plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html) tlt = re.findall(r'\"raw_title\"\:\".*?\"',html) for i in range(len(plt)): price = eval(plt[i].split(':')[1]) title = eval(tlt[i].split(':')[1]) ilt.append([price , title]) except: print("") def printGoodsList(ilt): tplt = "{:4}\t{:8}\t{:16}" print(tplt.format("序号", "价格", "商品名称")) count = 0 for g in ilt: count = count + 1 print(tplt.format(count, g[0], g[1])) def main(): goods = 'python web' depth = 3 start_url = 'https://s.taobao.com/search?q=' + goods infoList = [] for i in range(depth): try: url = start_url + '&s=' + str(44*i) html = getHTMLText(url) parsePage(infoList, html) except: continue printGoodsList(infoList) main()
运行结果:

来源:http://www.cnblogs.com/ST-2017/p/8414860.html