Response对象的属性:

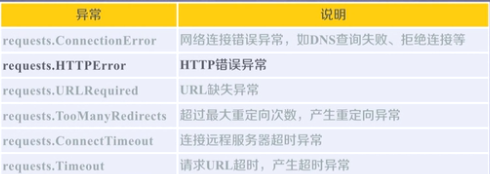
Requests库的异常:

爬虫通用代码框架:
url = "https://item.jd.com/2967929.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding # 正确的编码显示
print(r.text[:1000])
except:
print("爬取失败!")
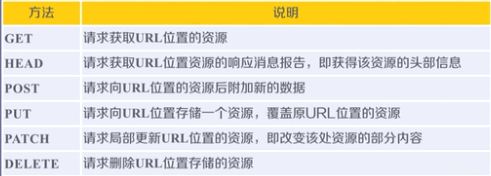
Requests库的7大方法:

关于HTTP协议:
HTTP,超文本传输协议。是一个基于“请求与响应”模式的、无状态的应用层协议。
HTTP协议采用URL作为定位网络资源的标识。
URL格式:http://host[:port][path],URL是通过HTTP协议存取资源的Internet路径。
HTTP协议对资源的操作(6大方法):

网络爬虫的规模:

Robots协议:
Robots Exclusion Standard 网络爬虫排除标准
作用:网站告知网络爬虫哪些页面可以抓取,哪些不行。Robots协议是建议但非约束性的,不遵守存在法律风险。
形式:在网站根目录下的robots.txt文件。如:http://fanyi.youdao.com/robots.txt
例子
# ip地址归属地查询
url = "https://ipchaxun.com/"
kv = {'user-agent':'Mozilla/5.0'}
try:
r = requests.get(url + '202.204.80.112', headers=kv)
r.raise_for_status()
print(r.status_code)
r.encoding = r.apparent_encoding
print(r.text)
except:
print("爬取失败")
来源:CSDN
作者:ngc1277
链接:https://blog.csdn.net/weixin_38121168/article/details/104692669