数据驱动方法
语义鸿沟
对于一幅图像,人眼看到的是猫,计算机看到的是数字矩阵。猫的标签和数字矩阵间的差距就是语义鸿沟。
如何把标签和数字矩阵联系起来(事实上就是图片分类)对计算机来说是一个很难的问题。
问题1:如何把它们联系起来?
问题2:当我们移动相机,从另一个方向拍摄猫的照片时,图像上的数字几乎都改变了,但是它还是表示同一只猫。如何才能把变化后的图像也认成猫?
光线改变时,它还是猫
这些不同姿势的还是猫
我们没有直接的方法识别一只猫。一个较直接的想法就是,先识别出耳朵,眼睛等,然后写一些方法来识别它。比如耳朵、眼睛等符合一定条件的就是猫。
但这并不是一个很好的方法。首先,这种算法很容易出错(看上面神奇的姿势);其次,识别其他的东西又需要设计新的算法。
所以我们考虑用数据驱动的方法。
数据驱动方法
首先获取带标签的数据集,然后训练分类器,得出一个模型,模型已经总结出识别的要素。最后用模型识别新的图片。
函数不再是只有一个(输入图片,识别它是否是猫),而是有两个,一个训练函数(用数据集来训练模型),一个预测函数(使用模型来识别这是不是一只猫)。
k最临近算法(KNN)
在KNN中训练函数的任务是记住训练集里所有的数据和标签;预测函数的任务是找到和输入图片最相似的k张图片,输入图片的标签就是最相似图片的标签
当k=1时,假设训练集里有N张图片,那么训练函数的复杂度就是O(1),因为无论数据集多大,所需要的时间都是固定的;预测函数的复杂度为O(N),因为每张图片要和N张训练集中的图片进行对比,所以预测函数需要的时间比较久。
但其实我们想要的算法是:训练可以花费长点时间(一般在数据中心训练),但是预测要快(希望能运行在浏览器、手机端等)。卷积神经网络正是这样的算法(预测快)。
下面是一个cifar10的例子。左边的一列是输入图像,右边的第一列就是最相似的图片,红色方框代表预测错误,绿色方框代表预测正确。可以看到正确率并不是很高。
才说到最相似的图片,我们该如何比较两张图像的相似度呢?
距离度量方法
L1距离
就是两个矩阵对应位置相减,然后把得到的矩阵的元素加起来。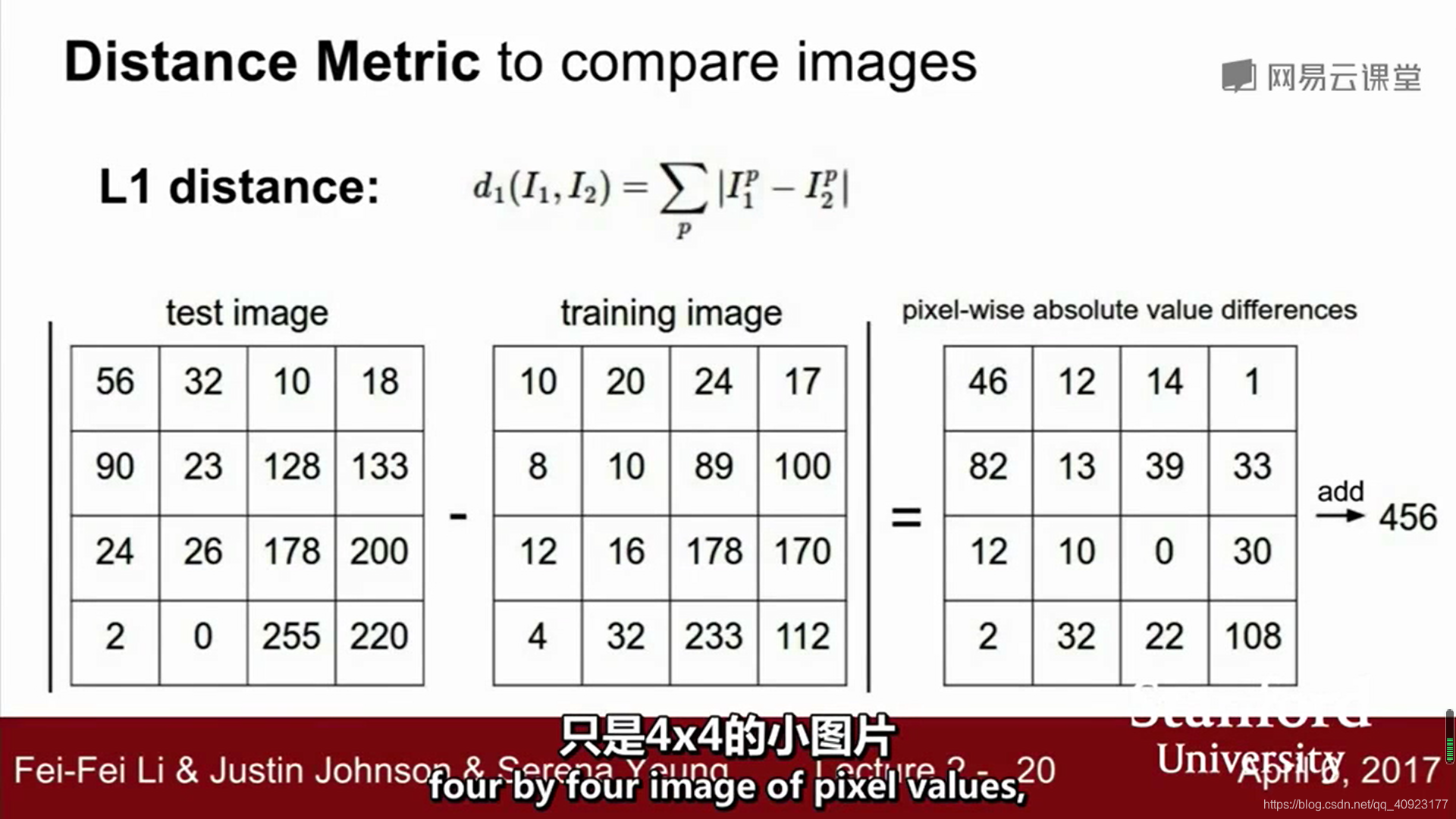
L2距离
L1距离取决于坐标系,当旋转坐标轴,不同点间的L1距离可能会改变而L2距离不会随坐标轴改变
如果输入向量中某些值有特定含义,比如一个表示员工的向量,其中元素表示年龄、薪资等含义时,可能使用L1距离更好一些。但如果是空间中的一个通用向量,不知道每个元素代表什么,可能使用L2更好。
除了L1、L2距离,还可以定义很多其他的距离。比如:要建立一个关于文本的KNN,你可以定义两句话之间的距离。
K的选择
我们来看一下KNN运行后的样子(k=1,L1)。
训练数据是带颜色的点,带颜色的区域原来是没有颜色的,颜色是通过最近点预测出来的。比如绿色的区域之所以是绿色的是因为区域中的每一个点最近的点都是绿色的。
但是从图中可以看到一些问题。绿色中间有一块区域是黄色的,可能它实际上应该是绿色的,因为那一片都是绿色的。
我们可以找到最相似的k(KNN中k的含义)个点而不是1个点,然后选择票数最多的标签,这样鲁棒性更好。
可以看到K=3时中间的黄色区域已经没有了,也变得更加平滑了。
白色区域是有两个或多个颜色票数一样,都是最高。比如k=3时,白色区域代表最近的3的点的颜色都是不同的,没有一种颜色的票数比其他颜色的都高。
超参数
超参数就是像KNN中的k和距离,我们不一定能从训练数据中学习到的参数。它有可能是在训练之前就需要设定好的。
实际上这些参数决定于实际问题,前人有一些总结。你也可以都试一下,看看哪一个更好。
哪个更好的好是怎么定义的呢?
方法1:选择在训练数据集中表现最好的,KNN中k=1时,它会得到100%的准确率。但是这个模型对于训练数据集之外的数据就很糟糕了,但是我们想要的正是在训练数据集外表现得很好的模型。所以这个方法不可行。
方法2:分为训练数据集和测试数据集,选择在测试数据集上表现得更好的那个。这个方法看起来不错,事实上也是一个很糟糕的方法。因为你不知道模型在新的数据集上表现得怎么样。因为测试数据集无法代表新的数据。
方法3:分为三个部分,一个训练集,一个验证集,一个测试集。
训练集用来训练参数,验证集用来选超参数,做完这些后得到一个模型,最后在测试数据集上运行,得到的结果才是你写到论文里的结果。这才是模型在新数据集上的表现。
必须分隔验证集和测试集,在最后才接触测试集,确保没有收到测试集的干扰。
当然,测试集可能不能代表真实世界,这就是建立数据集的人需要考虑的问题。一般都是一次性收集很多的数据,把它们打乱,随机分为训练集、测试集等。
如果你使用较早收集到的数据作为训练集,较晚收集的数据作为测试集,这就会造成偏差。
方法4:另一个设置超参数的策略是交叉验证,在小数据集上更常用,一般深度学习用不到,因为运算量很大。
首先把测试集分离出来,然后对剩下的数据集分为n份,比如这里就是5份,然后每一次都拿一份来做验证集,其他的是训练集。
比如:第1,2,3,4份作为训练集,第5份作为验证集。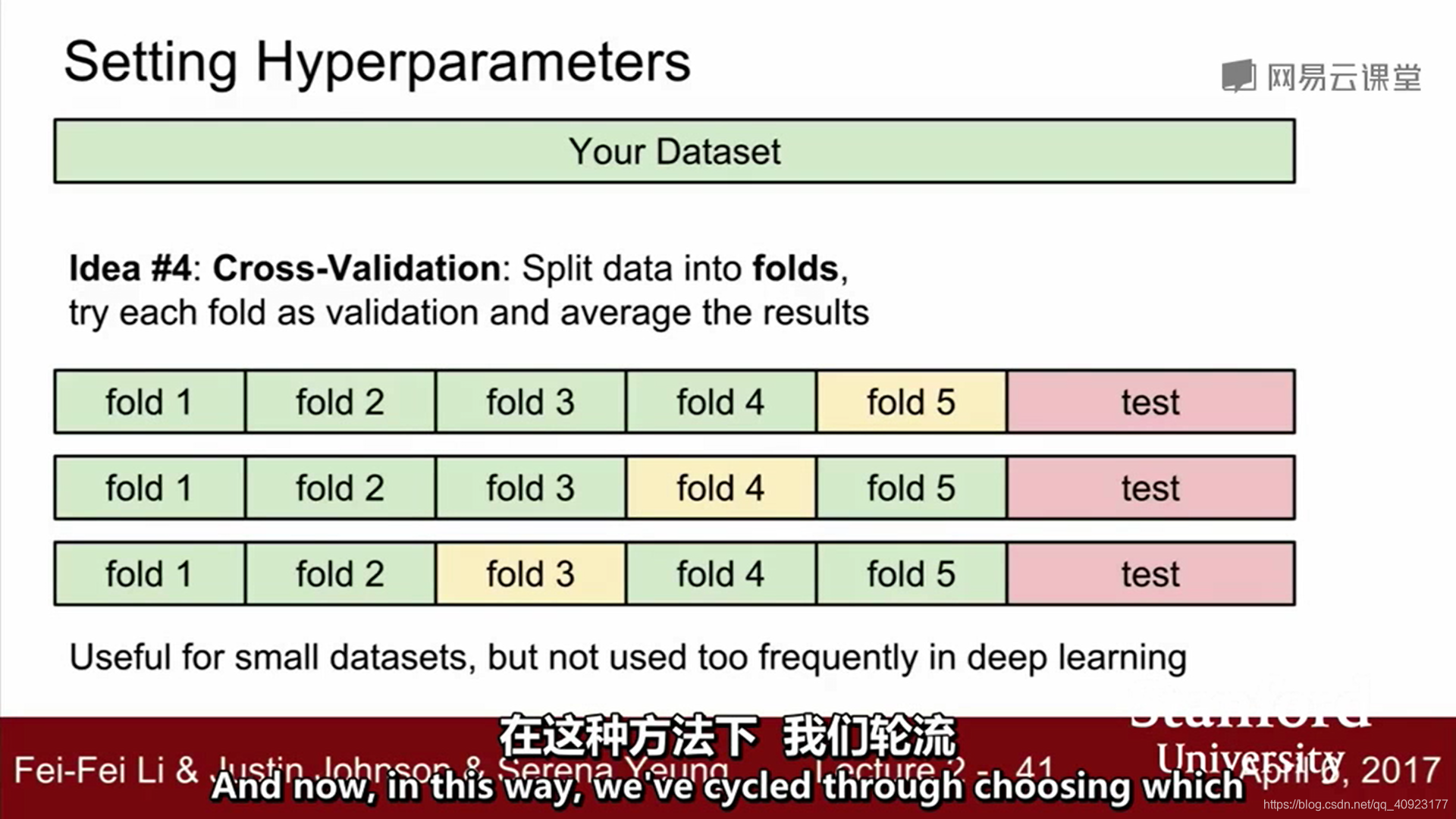
训练的最后能得出这样一张图
横坐标代表k,纵坐标代表准确率。每个k都有5个准确率,用来验证k的好坏
训练一个机器学习模型的时候,应该有这样一张图来表现算法的表现与超参数间的关系,然后选出表现最好的模型
可以看出在k=7时表现最好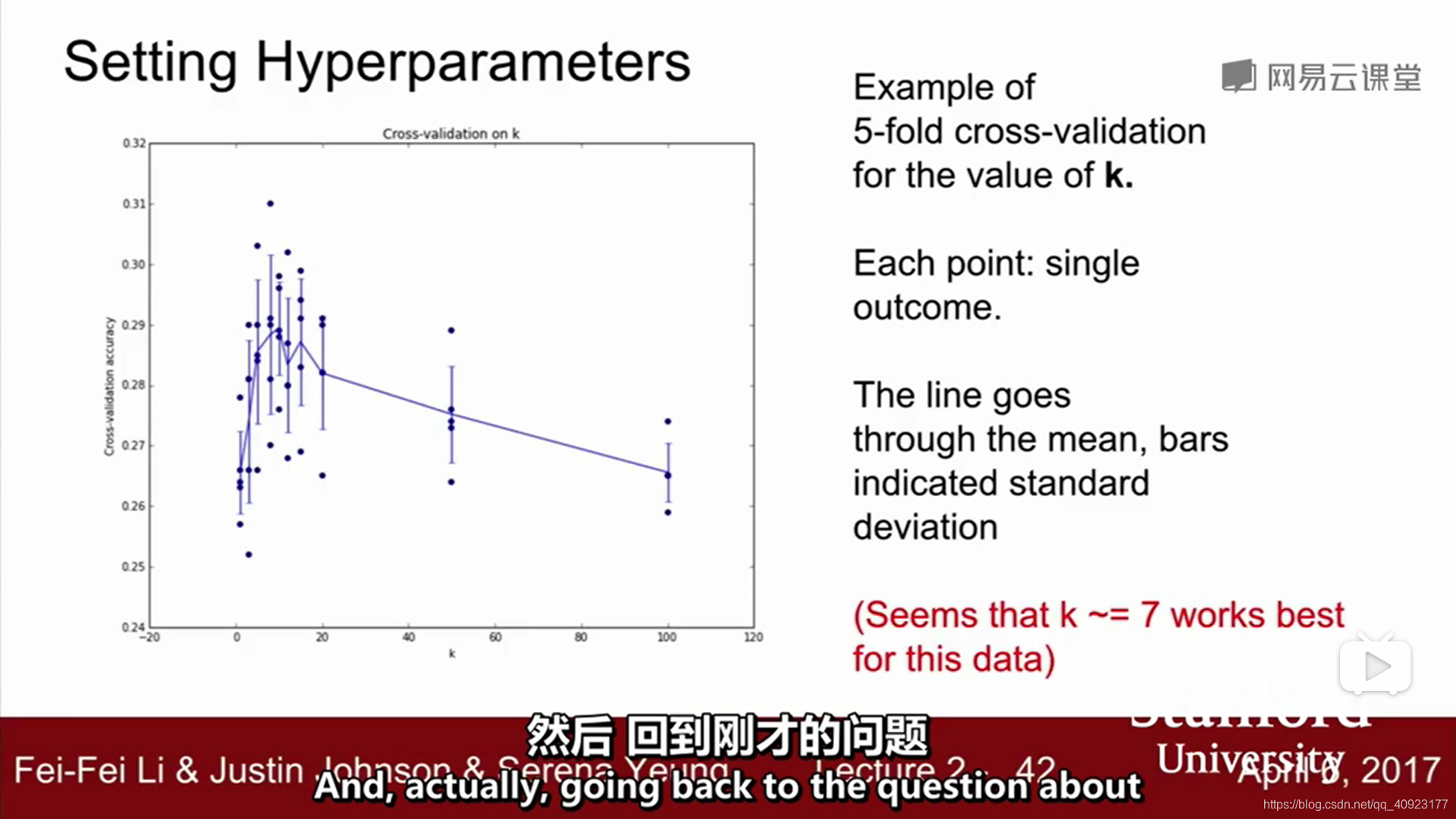
KNN的问题
但是KNN在图像中几乎不会用到,因为:
测试时非常慢
我们说过想要一种在测试时比较快的模型,因为模型可能是运行在较小的终端的。
距离度量的问题
L1、L2这种向量化的距离函数并不适合表示图像间的相似度。
第二幅图遮住嘴,第三幅图向下移动了,第四幅图色调变了,但是它们与第一幅图的L2距离都是一样(故意设计成L2距离一样的),这样并不是我们想要的。我们会觉得第三幅图像和第一幅图像最近,第二幅与第一幅相差较远。
维度灾难
KNN还有一个问题是维度灾难。KNN是要找到相近的k个点,但是如果训练数据集分布不均匀,KNN得到的结果可能和真实结果相差较远。
比如一个气球,数据点全部在气球表面上,气球表面是有质量的而气球中心没有。如果我们用KNN求气球中心的质量,它的最临近的k个点都是有质量的(数据点都分布在表面),所以最后的结果是中心点也是有质量的,但是这与实际情况不符。
所以说KNN要表现得好,就需要在空间上有密集的数据点,当空间的维度增长时,需要的训练数据就成指数级增长。指数级增长出来都不是好消息。
当一维时,需要4个点的数据才能满足要求,二维时需要16个点的数据,三维需要64个点的数据。可能我们并没有办法得到这么多点的数据。
总结
1.在图像分类中,我们用训练集中的图像和标签去训练数据,在测试集上预测模型的好坏
2.KNN预测标签是基于最近的k个图片的标签
3.不同的距离度量和k是超参数
4.通过验证集选择超参数,最后仅在测试集上运行一次,看看你的方法到底多好
来源:CSDN
作者:树天先森
链接:https://blog.csdn.net/qq_40923177/article/details/103838018