因为学习需要,想自己弄一些语料玩玩,新闻联播似乎是个不错的选择,然后百度了一下:
感觉还是挺多的。。。。所以我选择了第二个。。就是http://www.xwlbo.com/txt.html这个网址。
看了一下,这个网址是以_1的方式翻页的。


一共有47页,数据追溯到
似乎还可以。。。。
分析了下源代码。列表页的文章是用一个列表维护的:
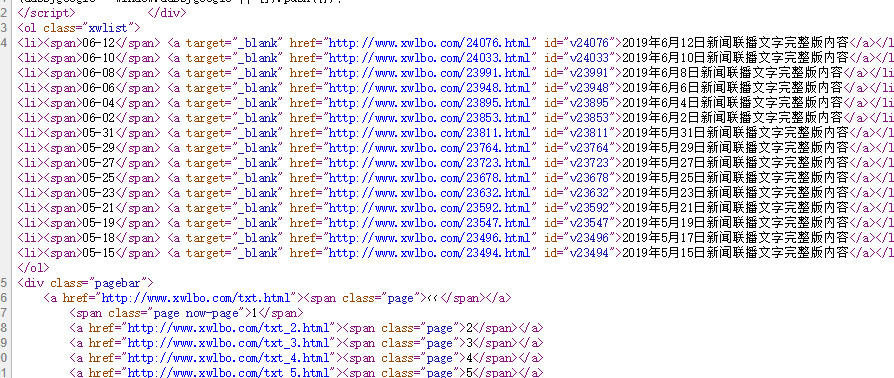
文章内的文字爬取难度一般,但是比较乱

我的思路是:
先爬取文章ID号,再遍历ID号爬一遍各个ID下的新闻的内容
那就, 直接上代码:
python爬虫爬取网站内容时,如果什么也没带,即不带报头headers,往往会被网站管理维护人员认定为机器爬虫,所以我们需要伪装浏览器的user-agent。
这个是网上的模板,用来随机组成User-Agent#settings.py User_Agents =[
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
]获取文章的ID号
import random
import re
import requests
import codecs
from spider.settings import User_Agents
class ID_Spider(object):
def __init__(self):
#URL
self.ur1 = "http://www.xwlbo.com/txt_"
self.ur2 = ".html"
#Headers
self.headers = {'User-Agent': random.choice(User_Agents)}
self.output = open('d:\id.txt','w+')
def down_(self,offset):
resp = None
try:
resp = requests.get(self.ur1 + str(offset) + self.ur2 , headers = self.headers)
except Exception as e:
print(resp)
return resp
def get_(self,resp):
reg = r'li><span>(.*?)</a></li>{1}'
if resp:
return re.findall(reg ,resp.text ,re.S)
def id_(self,ss):
for t in ss:
# dr = re.compile(r'</span> <a target="_blank" href=')
dd = re.sub(r'</span> <a target="_blank" href=','', t)
# dr = re.findall(r'http://www.xwlbo.com/[0-9]*.html',dd)
dr = re.findall(r'\d{4,5}',dd)
# id = re.findall(r'\\d',dr)
try:
print(dr[0])
self.output.write(dr[0])
self.output.write('\n')
except Exception as e:
continue
def main():
ids = ID_Spider()
offset = 1
while(offset <= 47):
ids.id_(ids.get_(ids.down_(offset)))
offset += 1
if __name__ == '__main__':
main()获取文章
import randomimport re
import time
import requests
from spider.settings import User_Agents
id_file = open('d:\id','r')
class NEWS_Spider(object):
def __init__(self):
#URL
self.ur1 = "http://www.xwlbo.com/"
self.ur2 = ".html"
#Headers
self.headers = {'User-Agent': random.choice(User_Agents)}
self.output = open('d:\\news.txt','w+')
def down_(self,id):
resp = None
try:
resp = requests.get(self.ur1 + str(id) + self.ur2 , headers = self.headers)
except Exception as e:
print(resp)
print(resp)
return resp
def get_(self,resp):
reg = r'<p><strong><a href="\d{4,5}.html">(.*?)</p> </div>{1}'
# reg = r'body>(.*?)</body>{1}'
if resp:
return re.findall(reg ,resp.text ,re.S)
def news_(self,ss):
try:
ss = re.sub(r'<[^>]*>','',str(ss))
ss = re.sub(r'(新闻联播文字版)','',str(ss))
ss = re.sub(r'\*屏蔽的关键字\*', '', str(ss))
ss = re.sub(r"\['",'',str(ss))
ss = re.sub(r"']",'',str(ss))
self.output.write(ss)
except Exception as e:
print(ss)
def main():
news = NEWS_Spider()
list = []
list = id_file.readlines()
for i in list:
news.news_(news.get_(news.down_(int(i))))
# print(news.down_(i))
# time.sleep(100000)
if __name__ == '__main__':
main()
其实我两个爬虫的代码几乎一样。稍微有点改动。因为刚刚学习,所以技术欠佳。
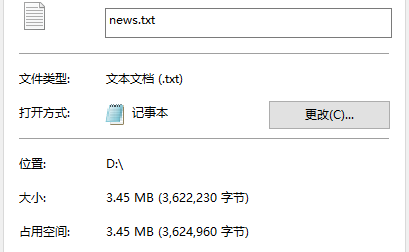
然后,大概就是这样,数据就弄好了。
来源:oschina
链接:https://my.oschina.net/u/4403178/blog/4254471