在爬取“安居客”网站时,本人主要遇到了2个问题:
1.网页数字加密
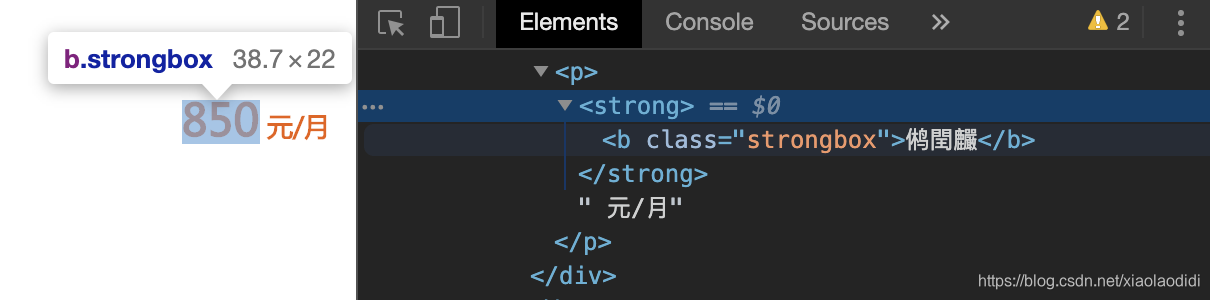
在浏览器里点击检查后,网页中显示数字的地方,在源代码中显示为加密后的乱码。
2.爬取部分内容后,requests无法访问报错。
这个报错,我在网上搜索了很多解决办法没有用(应该是访问过多,ip被封的原因)
解决方法
1.解密
(1)安装并倒入这几个库
from io import BytesIO
from fontTools.ttLib import TTFont
import base64
(2)从网页源代码中找到用于解码的代码
图中从bs4,之后到’)之间的内容,采用正则方式
import re
bs64_str = re.findall("charset=utf-8;base64,(.*?)'\)", p)[0]
(3)定义解密方法
def get_page_show_ret(mystr, bs64_str):
'''
mystr: 要转码的字符串
bs64_str: 转码格式
return: 转码后的字符串
'''
font = TTFont(BytesIO(base64.decodebytes(bs64_str.encode())))
c = font['cmap'].tables[0].ttFont.tables['cmap'].tables[0].cmap
ret_list = []
for char in mystr:
decode_num = ord(char)
if decode_num in c:
num = c[decode_num]
num = int(num[-2:]) - 1
ret_list.append(num)
else:
ret_list.append(char)
ret_str_show = ''
for num in ret_list:
ret_str_show += str(num)
return ret_str_show
(4)将采集的数据进行传入解密即可(本人采用xpath进行采集)
l = etree.HTML(p)
infos = l.xpath('//div[@class="zu-itemmod"]')
for info in infos:
title1 = info.xpath('.//h3//b/text()')[0]
title = get_page_show_ret(title1, bs64_str) #调用方法,传入参数。title1为需要解码的内容,bs64_str为第2步采集的代码
2.封ip解决
很多网站都有封ip的反爬措施,本人也使用了各种办法,包括比较复杂的构建redis代理池等,但都效果不太满意,最后发现采用selenium+chromdrive比较好用,但安装较复杂,且速度较慢,本文不做介绍了,如果需要学习使用selenium,可以查看其他相关博文。
[Python3爬虫]selenium+chromdriver可见即可爬
本人也是初学者,如有其他问题,欢迎大家一起探讨学习。
来源:CSDN
作者:xiaolaodidi
链接:https://blog.csdn.net/xiaolaodidi/article/details/104605693