工具:
pycharm 2019.3.1
anaconda3
注:安装完成anaconda后无需再安装Python,anaconda已经集成了Python编译环境。安装anaconda这个全家桶即可。
具体下载网址:
(官网即可,请自主匹配合适版本)
pycharm(社区免费版):https://www.jetbrains.com/pycharm/
anaconda:https://www.anaconda.com/
操作步骤:
1、锁定网址类型,获取页面信息(Chrome or 火狐)
① F12调出开发者工具,定位network,刷新页面加载获取:

② 锁定header,找到页面URL、cookie:
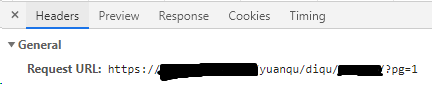
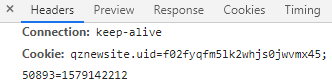
注:一般的连接都是采用 keep - alive形式
2、代码实现
① 加载相关库:
from urllib.parse import urljoin
import requests
import xlrd
import xlwt
from xlutils.copy import copy
from bs4 import BeautifulSoup
import time
②创建xls文件,用于存储数据:
index = len(value) # 获取需要写入数据的行数
workbook = xlwt.Workbook() # 新建一个工作簿
sheet = workbook.add_sheet(sheet_name) # 在工作簿中新建一个表格
for i in range(0, index):
for j in range(0, len(value[i])):
sheet.write(i, j, value[i][j]) # 像表格中写入数据(对应的行和列)
workbook.save(path) # 保存工作簿
③爬取页面信息:
hd = {
"Cookie": " ", # 页面信息填入
"User-Agent": " " # 页面信息填入
}
for num in range(1, 20):
print("第%d页开始爬取" % (num)) # 多页爬取
r = requests.get("https://xxxxxxxxxxx/?pg=%d" % (num), headers=hd) #需要获取信息的网站,多页获取
r.encoding = r.apparent_encoding
h_text = r.text
soup = BeautifulSoup(h_text, "html.parser")
links = soup.find_all("tr") # 查看页面源码,锁定表格,定位标签
items = []
for trs in links:
tds = trs.find_all('td') # 锁定表格数据,定位标签,这里是获取表格所有字段
i = 0
item = []
for td in tds:
if (td.a):
if (i >= 1):
item.append("https://f.qianzhan.com%s" % (td.a.get('href')))
break
i = i + 1
item.append(td.string)
if (item):
items.append(item)
print("第%d页开始写入" % (num))
write_excel_xls_append(book_name_xls, items)
print("第%d页写入成功" % (num))
print(' ')
④ 运行程序,等待结果
数据已经读取至Excel。
来源:CSDN
作者:vickie_tes
链接:https://blog.csdn.net/vickie_tes/article/details/104000300