Kafka简介
根据官网介绍,kafka主要有3种功能
- 发布和订阅消息流,类似于一个消息队列;
- 以容错的方式记录消息流,它以文本的方式来存储流;
- 可以在消息发布的时候就进行处理;
使用场景
- 构建实时的数据流管道;
- 构建实时的数据流应用,可以转换和响应数据流;
- 流处理、流传输
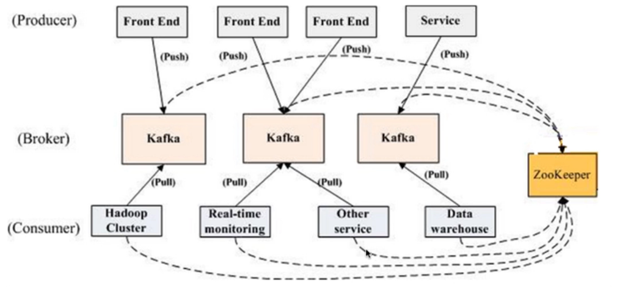
kafka组件
producer::消息和数据的生产者,向kafka的一个topic发布一个消息的进程、代码、服务
consumer::消费者,订阅数据并且处理其发布的消息的进程、代码、服务
consumer group::逻辑概念,对于同一个Topic,会广播给不用的Group,一个group,只有一个consumer可以消费该消息
broker::物理概念,kafka集群中的每个kafka节点
topic:逻辑概念,kafka消息的类别,对数据进行区分,隔离
Partition:物理概念,kafka下数据存储的基本单元。一个topic数据会被分散存储到多个Partition,每一个Partition是有序的
replication::同一个partition可能会有多个replica(副本),多个replica之间数据是一样的
当集群中有Broker挂掉,系统可以主动使Replicas提供服务
replication leader:负责该Partition上与Producer和consumer交互
replicManage:负责管理当前Broker所有分区和副本的信息,处理kafakController发起的一些请求,副本状态切换、添加、读取消息
Producer API
ConsumerAPI
Stream API
Connectors API
Kafka消息结构
偏移、消息长度、校验消息完整性、快速判断是否是kafka消息、当前消息属性(可选字段)、时间戳,Key、value

- At most once—Messages may be lost but are never redelivered.
- At least once—Messages are never lost but may be redelivered.
- Exactly once—this is what people actually want, each message is delivered once and only once.
consumer消费消息的方式有以下2种;
-
consumer读取消息,保存offset,然后处理消息。
现在假设一个场景:保存offset成功,但是消息处理失败,consumer又挂了,这时来接管的consumer
就只能从上次保存的offset继续消费,这种情况下就有可能丢消息,但是保证了at most once语义。 -
consumer读取消息,处理消息,处理成功,保存offset。
如果消息处理成功,但是在保存offset时,consumer挂了,这时来接管的consumer也只能
从上一次保存的offset开始消费,这时消息就会被重复消费,也就是保证了at least once语义。
第一种对应的代码:
List<String> messages = consumer.poll();
consumer.commitOffset();
processMsg(messages);
第二种对应的代码:
List<String> messages = consumer.poll();
processMsg(messages);
consumer.commitOffset();
Producer端的消息幂等性保证
每个Producer在初始化的时候都会被分配一个唯一的PID,
Producer向指定的Topic的特定Partition发送的消息都携带一个sequence number(简称seqNum),从零开始的单调递增的。
Broker会将Topic-Partition对应的seqNum在内存中维护,每次接受到Producer的消息都会进行校验;
只有seqNum比上次提交的seqNum刚好大一,才被认为是合法的。比它大的,说明消息有丢失;比它小的,说明消息重复发送了。
以上说的这个只是针对单个Producer在一个session内的情况,假设Producer挂了,又重新启动一个Producer被而且分配了另外一个PID,
这样就不能达到防重的目的了,所以kafka又引进了Transactional Guarantees(事务性保证)。
Transactional Guarantees 事务性保证
kafka的事务性保证说的是:同时向多个TopicPartitions发送消息,要么都成功,要么都失败。
为什么搞这么个东西出来?我想了下有可能是这种例子:
用户定了一张机票,付款成功之后,订单的状态改了,飞机座位也被占了,这样相当于是
2条消息,那么保证这个事务性就是:向订单状态的Topic和飞机座位的Topic分别发送一条消息,
这样就需要kafka的这种事务性保证。
这种功能可以使得consumer offset的提交(也是向broker产生消息)和producer的发送消息绑定在一起。
用户需要提供一个唯一的全局性TransactionalId,这样就能将PID和TransactionalId映射起来,就能解决
producer挂掉后跨session的问题,应该是将之前PID的TransactionalId赋值给新的producer。
Consumer端
以上的事务性保证只是针对的producer端,对consumer端无法保证,有以下原因:
- 压实类型的topics,有些事务消息可能被新版本的producer重写
- 事务可能跨坐2个log segments,这时旧的segments可能被删除,就会丢消息
- 消费者可能寻址到事务中任意一点,也会丢失一些初始化的消息
- 消费者可能不会同时从所有的参与事务的TopicPartitions分片中消费消息
如果是消费kafka中的topic,并且将结果写回到kafka中另外的topic,
可以将消息处理后结果的保存和offset的保存绑定为一个事务,这时就能保证
消息的处理和offset的提交要么都成功,要么都失败。
如果是将处理消息后的结果保存到外部系统,这时就要用到两阶段提交(tow-phase commit),
但是这样做很麻烦,较好的方式是offset自己管理,将它和消息的结果保存到同一个地方,整体上进行绑定,
Kafka特性
分布式:
多分区、多副本、多订阅者、基于zookeeper调度
高性能:
高吞吐量、高并发、低延迟、时间复杂度O(1)
1.顺序读写
kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能
2.零拷贝
在Linux kernel2.2 之后出现了一种叫做"零拷贝(zero-copy)"系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”
3.分区
kafka中的topic中的内容可以被分为多分partition存在,每个partition又分为多个段segment,所以每次操作都是针对一小部分做操作,很轻便,并且增加并行操作的能力
4.批量发送
kafka允许进行批量发送消息,producter发送消息的时候,可以将消息缓存在本地,等到了固定条件发送到kafka
- 等消息条数到固定条数
- 一段时间发送一次
5.数据压缩
Kafka还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩
压缩的好处就是减少传输的数据量,减轻对网络传输的压力
批量发送和数据压缩一起使用,单条做数据压缩的话,效果不明显
持久性和扩展性:
数据持久化、容错性、支持在线水平扩展、消息自动平衡
应用
消息队列、行为跟踪、元信息监控、日志收集、流处理、
事件源(回溯事件)、持久性日志
来源:https://www.cnblogs.com/Samuel1/p/9851293.html