名字
问题
一、简介
优点:
缺点:
二、继承关系图
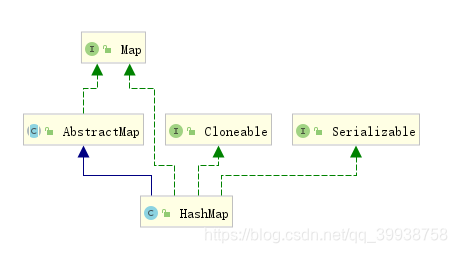
是浅拷贝
HashMap实现了Cloneable,可以被克隆,是浅拷贝。
HashMap实现了Serializable,可以被序列化。
HashMap继承自AbstractMap,实现了Map接口,具有Map的所有功能。
三、存储结构
四、源码分析
/* 介绍
HashMap是一个散列表。他存储的内容是键值对(key-value)映射
HashMap继承AbstractMap,实现了Map,Cloneable、Serializable接口
HashMap的实现是不同步的,也就是线程不安全的,他的key、value都可以为null
HashMap的映射不是有序的
HashMap的实例有2个参数影响其性能:“初始容量”和“加载因子”。
容量:是哈希表中桶的数量,通常默认为8
加载因子:是哈希表在其容量自动增加之前可以达到多满的一种尺度。通常默认为0.75
rehash操作:当哈希表中的条目数超过了加载因子与当前容量的乘积时,则要对该哈希表进行rehash操作(即重构内部数据结构)。从而哈希表讲具有大约两倍的桶数
通常默认加载因子为0.75,这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但是同时也增加了查询成本(时间成本)。在设置初始化容量的时候应该考虑到映射中所需的条目数及其加载因子,以便最大限度的减少rehash操作次数。如果初始容量>最大条目数➗加载因子,则不会rehash操作。
*/
内部类
属性
/*
hashMap的属性介绍
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;//默认初始容量(数组大小),必须是2的幂
static final int MAXIMUM_CAPACITY = 1 << 30;//1073741824最大的容量范围,必须是2的幂
static final float DEFAULT_LOAD_FACTOR = 0.75f;//加载因子默认值0.75
transient Entry[] table;//存储数据的entry数组
transient int size;//数组的大小(map中保存键值对的数量)
int threshold;//临界值=加载因子*初始容量(当size大于临界值就会出现数组扩充到原来2 倍)
final float loadFactor;//加载因子(默认DEFAULT_LOAD_FACTOR=0.75)
transient volatile int modCount;//map结构被改变的次数
//如果桶的结点数大于8时,有可能回转化为树(红黑树),初始为链表
//当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
//在哈希表扩容时,如果发现桶的结点数小于6,则会由树重新退化为链表
//当桶(bucket)上的结点数(链表长度)小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
//在转化树(红黑树)之前还有一次判断,
//如果键值对(每个桶的数量+)的数量大于64时才会进行树化(链表转化红黑树)
//如果当前容量小于它,就不会将链表转化为红黑树,而是用resize()代替
static final int MIN_TREEIFY_CAPACITY = 64;
//存放具体元素的集
transient Set<Map.Entry<K,V>> entrySet;
构造
/*
HashMap的构造函数有4个
*/
/* 第一种构造HashMap()*/
public HashMap(){
//加载因子采用默认0.75,原因同上,时间/空间折衷。
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
/* 第二种构造HashMap(int,float)*/
public HashMap(int initialCapacity, float loadFactor){
//如果初始化容量小于0 抛IllegalArgumentException异常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//如果初始化容量大于2147483647(1 << 30)时,就设置为2147483647 (int的最大值)
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//如果设置加载因子<= 0 或 不能是NaN,例如0.0f/0.0f=NaN 就是NaN
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
//如果传入的初始化容量不是2的幕数则进行补足为2的幕数,
//补足后超过MAXIMUM_CAPACITY容量则设置为MAXIMUM_CAPACITY
this.threshold = tableSizeFor(initialCapacity);
}
/* 第三种构造HashMap(int) */
public HashMap(int initialCapacity){
//初始化容量为8 加载因子为0.75
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/* 第四种构造HashMap(Map)*/
public HashMap(Map<? extends K, ? extends V> m){
//初始化加载因子为0.75
this.loadFactor = DEFAULT_LOAD_FACTOR;
//设置容量threshold为:m.size()转化为2的幕数结果(因为是构造创建,所以table为null)
//
putMapEntries(m, false);
}
主要方法
hash方法
resize();
/* 获得key的hash值(下面有hash计算图)*/
static final int hash(Object key) {
int h;
// 1、如果key==null 返回0
// 2、获得key的hashCode值,赋值给h。
// 3、h >>>16 按位右移补零操作符。
// 左操作数的值按右操作数指定的位数右移,移动得到的空位以零填充。
// >>>和>>不同的是>>不会在移动得到的空位以零填充
// 4、把2的结果和3的结果进行 ^ 运算
// 如果相对应位值相同,则结果为0,否则为1
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
resize方法
/* 重新计算容量
向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素;
当然java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组;就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
*/
final Node<K,V>[] resize() {
//保存当前table(一个数组下面是链表或者红黑树存储)
Node<K,V>[] oldTab = table;
//保存当前容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//保存当前临界值(阔值)(加载因子*容量)
int oldThr = threshold;
int newCap, newThr = 0;
//之前的table大小大于0,则已初始化
if (oldCap > 0) {
//如果超过最大值就不扩充了,只设置临界值(阔值)
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//扩容(如果扩容后容量还<16,此次不设置临界值
//则需在下面的 if(newThr==0)处重新计算临界值[阔值])
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//如果老的table没有值 但有阔值,则初始容量设置为老的阈值
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
//如果老的table没有值 且老的临界值=0,则使用缺省值(使用默认构造函数初始化)
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的阔值 (上面第一和第二都会出现新阔值为0)
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//把newThr赋予给阔值
threshold = newThr;
//初始化table
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//之前的table已初始化过
if (oldTab != null) {
//循环复制元素
for (int j = 0; j < oldCap; ++j) {//扩容后进行rehash操作
Node<K,V> e;
if ((e = oldTab[j]) != null) {//如果==null,无节点不做处理
oldTab[j] = null;//通知gc回收
//桶中只有一个节点,直接重新计算index并赋值
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//hashMap.TreeNode继承LinkedHashMap.Entry继承HashMap.Node实现Map.Entry接口
//如果是树节点,采用红黑树处理方式,跟链表的处理相似#李雷#:等待红黑树学习了看
//根据(e.hash & oldCap)分为两个,如果哪个数目不大于UNTREEIFY_THRESHOLD,就转为链表
else if (e instanceof TreeNode)
//转化为TreeNode,并split
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//链表扩容#李雷#:等待链表学习后看,不是很明白
else { // preserve order
//进行链表复制
//方法比较特殊,它并没有重新计算元素在数组中的位置
//而是采用了 原始位置加原数组长度的方法计算得到位置。
//loHead用户存储低位(位置不变)key的链头,loTail用于指向链位位置。
Node<K,V> loHead = null, loTail = null;
//hiHead用户存储即将存储在高位的key的链头,hiTail用于指向链尾位置。
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
// 将同一桶中的元素根据(e.hash & oldCap)是否为0进行分割成两个不同的链表,完成rehash
do {
/*********************************************/
/**
* 注: e本身就是一个链表的节点,它有 自身的值和next(链表的值),但是因为next值对节点扩容没有帮助,
* 所有在下面讨论中,我近似认为 e是一个只有自身值,而没有next值的元素。
*/
/*********************************************/
next = e.next;
// 注意:不是(e.hash & (oldCap-1));而是(e.hash & oldCap)
// (e.hash & oldCap) 得到的是 元素的在数组中的位置是否需要移动,示例如下
// 示例1:
// e.hash=10 0000 1010
// oldCap=16 0001 0000
// & =0 0000 0000 比较高位的第一位 0
//结论:元素位置在扩容后数组中的位置没有发生改变
// 示例2:
// e.hash=17 0001 0001
// oldCap=16 0001 0000
// & =1 0001 0000 比较高位的第一位 1
//结论:元素位置在扩容后数组中的位置发生了改变,新的下标位置是原下标位置+原数组长度
// (e.hash & (oldCap-1)) 得到的是下标位置,示例如下
// e.hash=10 0000 1010
// oldCap-1=15 0000 1111
// & =10 0000 1010
// e.hash=17 0001 0001
// oldCap-1=15 0000 1111
// & =1 0000 0001
//新下标位置
// e.hash=17 0001 0001
// newCap-1=31 0001 1111 newCap=32
// & =17 0001 0001 1+oldCap = 1+16
//元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
// 0000 0001->0001 0001
next = e.next;//保存下一个节点
//与原数组长度相与后,得到的结果为0的,意味着在新数组中的位置是不变的,
//因此,将其组成一个链条
if ((e.hash & oldCap) == 0) { //说明
if (loTail == null)//第一个结点让loTail和loHead都指向它
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {//同上
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict)
五、总结
- 不全,仅供个人编辑
来源:CSDN
作者:菜鸟编程98K
链接:https://blog.csdn.net/qq_39938758/article/details/103489308