大规模数据实战
前后端处理分离解耦,前批处理+有向图编译,后端为有向图优化+自动资源分配+自动监控/错误跟踪 首先我们忘掉所有的框架,我们想做的业务设计其实是就是一个count() 一个topK() 衡量指标很简单是sla 工程一致性模型,强一致性,弱一致性,最终一致性 Cloud Spanner 就是强一致性,业务级的数据引擎 ''' 复制 过滤 分离 合并 ''' 可以使用发布订阅,进行解耦 削峰 cap c 线性一致性 分布式系统操作就像单机一样 a 可用性 只要不是所有节点都挂了,数据一定要返回响应 p 分区容错 ,就是数据不能仅仅存在一个节点上 存储架构使用的cp 系统 Google BigTable, Hbase, MongoDB Ap 系统 amazon dynamo 数据系统 kafka 属于ca 系统 批处理层 速度处理层 服务层 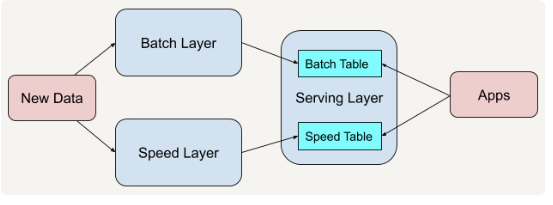 spark spark 不只能依赖于hadoop 才能使用,还可以运行在apache mesos ,kubernetes ,standalone ![](https://img2018.cnblogs.com/blog/1337375/201909/1337375