上一节基本流程中,只描述了DRF开发过程,但其中有很多不足,离实际应用还差得很远。
这一节,主要解决以下两个问题:
1 如果我们只需要使用一个表中的几个字段而不需要所有字段全部使用时,该怎么办?
2 如果我们临时需要在模型中增加几个字段,该怎么办?
1 创建ModelSerializer序列化器
在Applications/Examples/views下创建一个文件Serializer.py,内容如下:
from rest_framework import serializers
from Applications.Organizations.models import UserInfo
from rest_framework.viewsets import ModelViewSet
class UserInfoSerializer2(serializers.ModelSerializer):
"""
ModelSerializer序列化器,一般与表相关
"""
# 增加两个表中没有的临时字段
sms_code = serializers.CharField(label='短信验证码', write_only=True, help_text='短信验证码', min_length=6, max_length=6)
token = serializers.CharField(label='JWT Token', read_only=True, help_text='JWT Token')
class Meta:
model = UserInfo
fields = ('id', 'username', 'password', 'mobile', 'sms_code', 'token', 'openid')
# 此处为反序列化方法,在后面的文档中会详解。
# 但因字段sms_code是自定义的临时字段,增加或更新记录时,会报错,需要在此删除,故先提供。
def create(self, validated_data):
# 删除sms_code
del validated_data['sms_code']
user = UserInfo.objects.create(**validated_data)
return user
class UserInfoViewSet2(ModelViewSet):
"""
视图
"""
queryset = UserInfo.objects.all()
serializer_class = UserInfoSerializer2
2 创建视图
from django.urls import path
from Applications.Examples.views import ExpHome, CoreAPI
from rest_framework.routers import DefaultRouter
from .views.Serializer1 import UserInfoViewSet1
from .views.Serializer2 import UserInfoViewSet2
urlpatterns = [
path('ExpHome/', ExpHome.ExoHome.as_view()),
path('CoreAPI/', CoreAPI.CoreAPI.as_view()),
path('LoginHome/', CoreAPI.LoginHome.as_view()),
]
router = DefaultRouter() # 可以处理视图的路由器
router.register('UserInfo1', UserInfoViewSet1) # 向路由器中注册视图集
router.register('UserInfo2', UserInfoViewSet2) # 向路由器中注册视图集
urlpatterns += router.urls # 将路由器中的所以路由信息追到到django的路由列表中
3 运行测试
运行工程,可以看到以下界面:
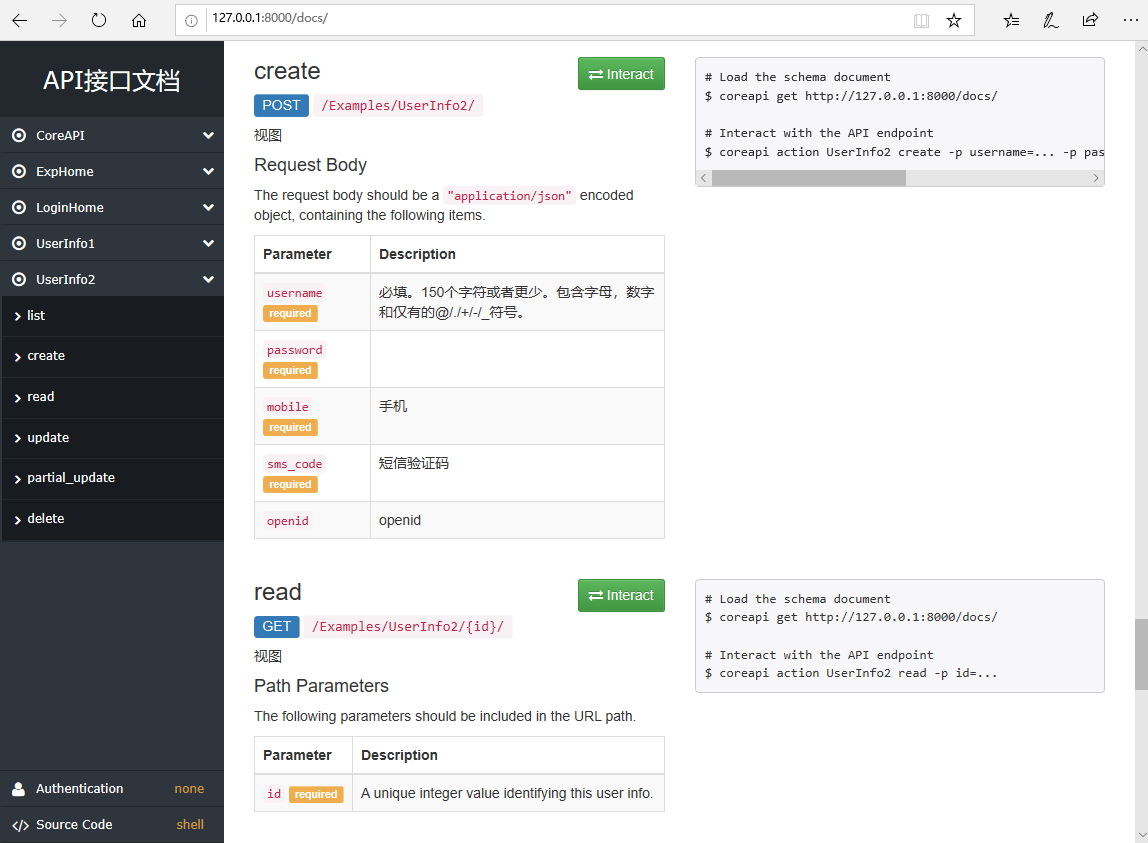
3.1 测试create接口
找到create接口,发现现在字段少了,fields提供了7个字段,此处只有5个了。还有2个呢?
这是因为id和token都是只读字段,id是django系统生成的自增字段,本身是只读的,而token是在增加定义字段中明确标识为只读字段。故在创建记录的时候,不能增加只读字段。
增加几条记录。
3.2 测试list接口
可以看到刚才录入的记录。但只有5个字段,这是因为sms_code和token两个字段是临时字段。只能用于新增和保存时提供数据,而两个字段的数据并没有存入数据库中,所以,查询的时候,是没有的。
3.3 测试read接口
根据ID查询,返回字段和list接口一样。
3.4 测试update
根据ID更新记录,返回更新后的数据。
3.5 测试partial_update
根据ID值,局部更新相应字段。除ID外,只更新输入了值的字段。
3.6 测试delete
根据ID值,删除当前记录
4 增加更改参数描述
从页面上发现,ID的描述是英文的,而password没有描述,username描述太多。这需要在序列化器中定义help_text。代码如下:
from rest_framework import serializers
from Applications.Organizations.models import UserInfo
from rest_framework.viewsets import ModelViewSet
class UserInfoSerializer2(serializers.ModelSerializer):
"""
ModelSerializer序列化器,一般与表相关
"""
# 增加两个表中没有的临时字段
sms_code = serializers.CharField(label='短信验证码', write_only=True, help_text='短信验证码', min_length=6, max_length=6)
token = serializers.CharField(label='JWT Token', read_only=True, help_text='JWT Token')
class Meta:
model = UserInfo
fields = ('id', 'username', 'password', 'mobile', 'sms_code', 'token', 'openid')
extra_kwargs = {
'id': {
'read_only': True,
'help_text': '用户ID'
},
'username': {
'help_text': '用户名',
},
'password': {
'write_only': True,
'help_text': '用户密码',
},
'mobile': {
'help_text': '手机号',
},
'openid': {
'help_text': '微信openid',
}
}
# 此处为反序列化方法,在后面的文档中会详解。
# 但因字段sms_code是自定义的临时字段,增加或更新记录时,会报错,需要在此删除,故先提供。
def create(self, validated_data):
# 删除sms_code
del validated_data['sms_code']
user = UserInfo.objects.create(**validated_data)
return user
class UserInfoViewSet2(ModelViewSet):
"""
视图
"""
queryset = UserInfo.objects.all()
serializer_class = UserInfoSerializer2
来源:https://www.cnblogs.com/dorian/p/12370266.html