
spark内核执行流程图
代表4个阶段
1构建RDD,进行join,groupBy,filter操作,形成DAG有向无环图(有方向,没有闭环),在最后一个action时完成DAG图,代表着数据流向
2提交DAG为DAGScheduler,DAG调度器,主要是将DAG划分成一个个stage,并且提交stage
切分的依据是宽依赖,也就是有网络的传递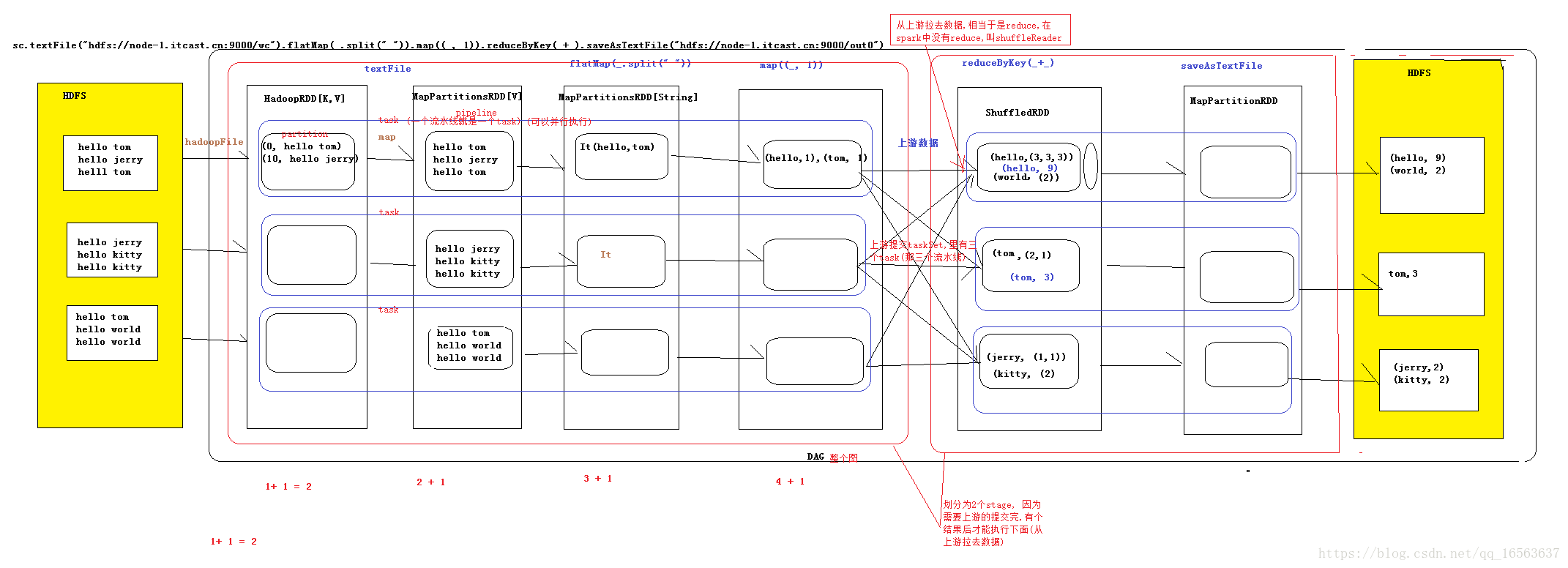
3TaskScheduler,Task调度器,启动task通过cluster manager(严格意义上是driver),先启动executer,再通过driver提交task到worker下面的executer.straggling tasks再起一个任务进行任务重置(如果100个任务99个完成一个没完成,起一个任务,和没完成的任务计算同样的数据)
4worker,executer开始执行task,block manager是管理分区的,在executer上面开线程,执行业务逻辑
管依赖和窄依赖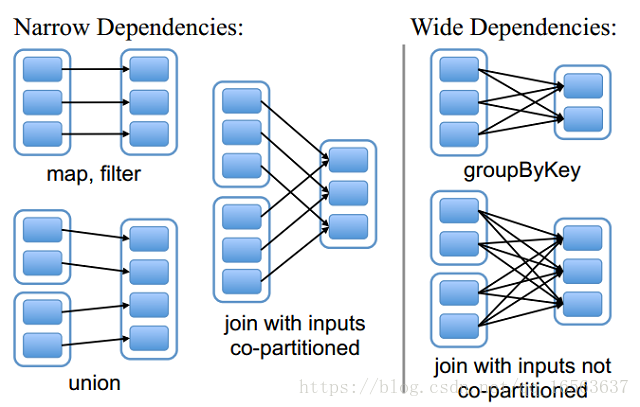
恢复的时候得根据依赖关系恢复(checkPoint)
窄依赖:父分区的数据只给一个子分区
宽依赖:父分区的数据给多个子分区
来源:CSDN
作者:qq_16563637
链接:https://blog.csdn.net/qq_16563637/article/details/82823276